Foi disponibilizada uma nova versão do Embrapa I/O (a 1.25.4) com novidades. Em resumo, temos as seguintes novas funcionalidades e melhorias:
- Busca ativa por CVEs com alertas na dashboard;
- Integração com GPU Servers para uso de LLMs nos projetos;
- Possibilidade de atualizar imagens e apagar containers no restart da build;
- Possibilidade de remover completamente a instância (deploy) de uma build; e
- Melhorias de segurança na integração de clusters.
A seguir, são detalhadas cada uma delas.
1. Busca ativa por CVEs com alertas na dashboard
A plataforma Embrapa I/O implementa agora a busca ativa por Vulnerabilidades e Exposições Comuns (do inglês, Common Vulnerabilities and Exposures - CVE) nas imagens das aplicações instanciadas em sua rede de clusters.
O CVE é um índice que padroniza a identificação de vulnerabilidades de segurança em softwares e sistemas. Cada CVE possui um identificador único (p.e., CVE-2025-12345), que descreve uma falha específica de segurança. Por meio deste identificador, pode-se buscar mais informações em bancos de dados especializados. No Embrapa I/O cada CVE é detectado por meio da ferramenta Trivy e está lincado ao National Vulnerability Database - NVD.
Quando os processos de varredura (scanner) detectam CVEs nas imagens utilizadas pelos containers das aplicações, é mostrado um ícone especial no botão de health check da build instanciada (a) no card do projeto:
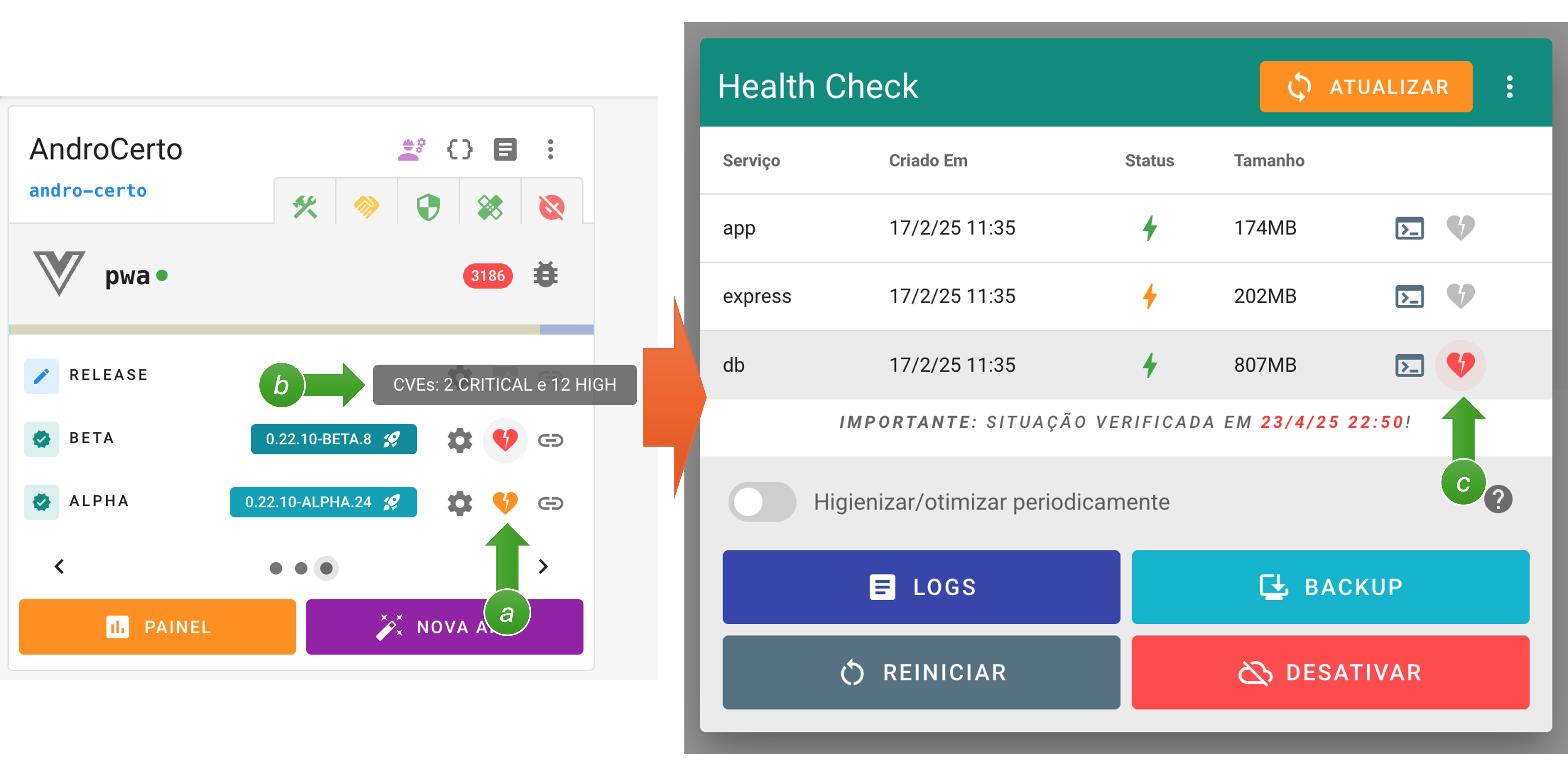
Se houver apenas CVEs de severidade “alta” (HIGH), será mostrado um ícone laranja. Porém se existirem CVEs de severidade “crítica” (CRITICAL), o ícone será vermelho. Acessando o painel de health check por este botão (b), pode-se ver exatamente qual(is) container(s) possui(em) imagens com CVEs identificados (c). Clicando sobre o ícone indicado, é mostrada a listagem das vulnerabilidades:
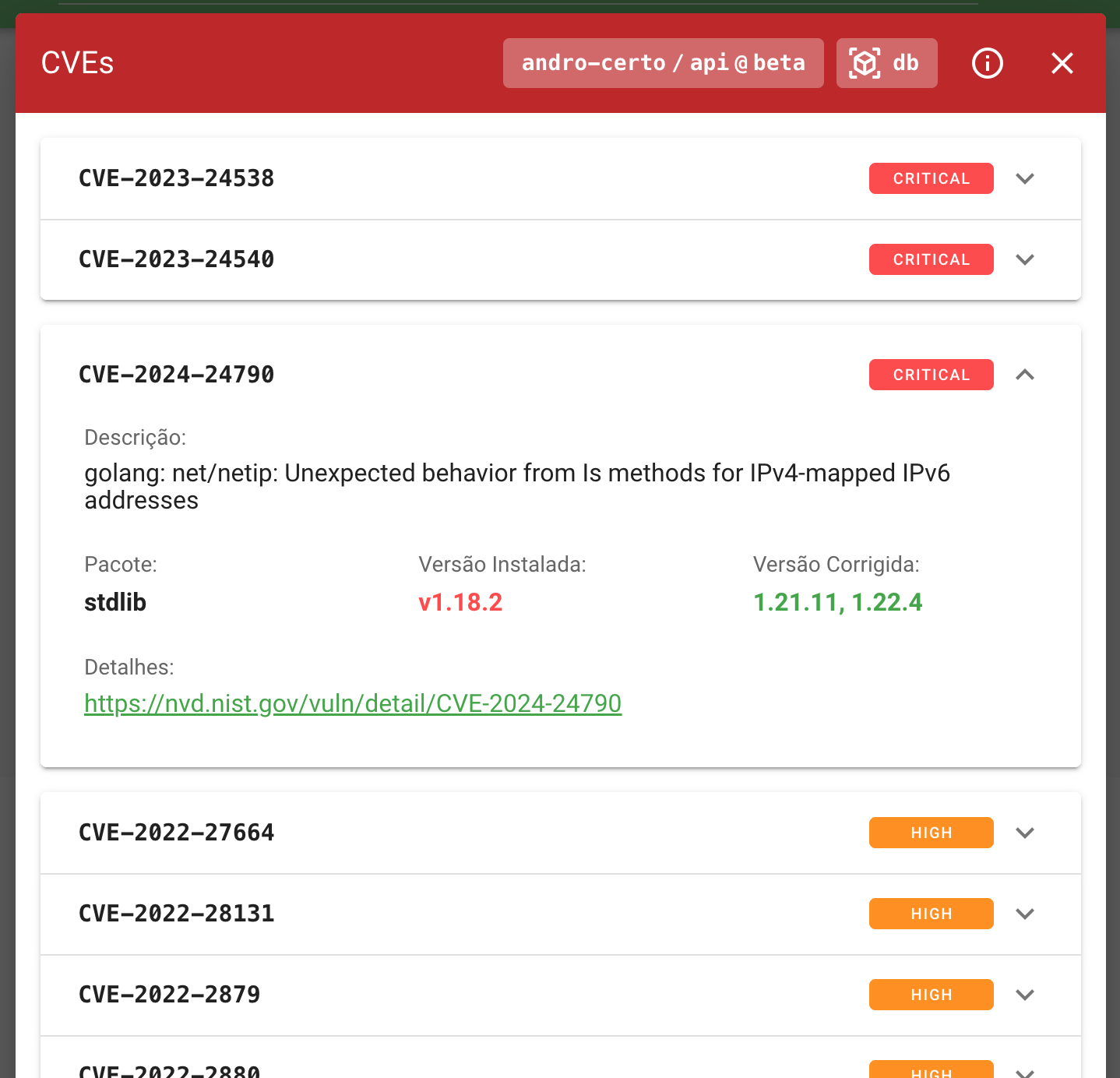
Além da descrição, pode-se verificar qual pacote está apresentando vulnerabilidade e qual a versão corrigida (para qual o mesmo deve ser atualizado).
Atenção! É importante ressaltar que as imagens são escaneadas a partir das builds instanciadas na rede de clusters da plataforma. Desta forma, deploys em servidores externos ao ecossistema do Embrapa I/O (instanciadas por meio do Releaser, p.e.) não serão contempladas. Assim, sugere-se fortemente que a rede de clusters seja utilizada, no mínimo, para o deploy de aplicações em estágio alpha (testes internos), de forma que o projeto possa se beneficiar desta funcionalidade.
Esta é mais uma feature da plataforma que visa fomentar o aprimoramento contínuo da qualidade das aplicações desenvolvidas na Embrapa (tanto em âmbito institucional, quanto para a agricultura digital), bem como ajudar a zelar pela segurança do ambiente digital da Empresa.
2. Integração com GPU Servers para uso de LLMs nos projetos
Visando viabilizar (e “democratizar”) o uso de Large Language Model - LLM nos projetos de desenvolvimento de software com uso da plataforma Embrapa I/O, está sendo estabelecida uma “Arquitetura de Referência em IA Generativa”. Esta arquitetura estabelece alguns boilerplates para o desenvolvimento de agentes de IA especializados por meio de Retrieval Augmented Generation - RAG e Prompt Engineering e integrados a APIs por meio de Model Context Protocol - MCP. Uma apresentação prévia destes conceitos e da arquitetura em si já foi realizada e está disponível no canal do YouTube do Embrapa I/O.
Dentre as especificidades desta arquitetura, está a disponibilização de GPU Servers integrados aos clusters de deploy de aplicações. Com isso, espera-se reduzir o custo de bilhetagem para uso de LLMs via APIs externas, zelar pelo sigilo e propriedade intelectual destes dados e possibilitar a criação de projetos exploratórios e provas de conceito (PoC) em IA generativa.
As LLMs nestes GPU Servers estão sendo disponibilizadas, em um primeiro momento, por meio do Ollama. No momento da escolha do cluster de deploy da build é possível visualizar se este recurso está disponível (a) e, neste caso, as configurações para uso do serviço (b):
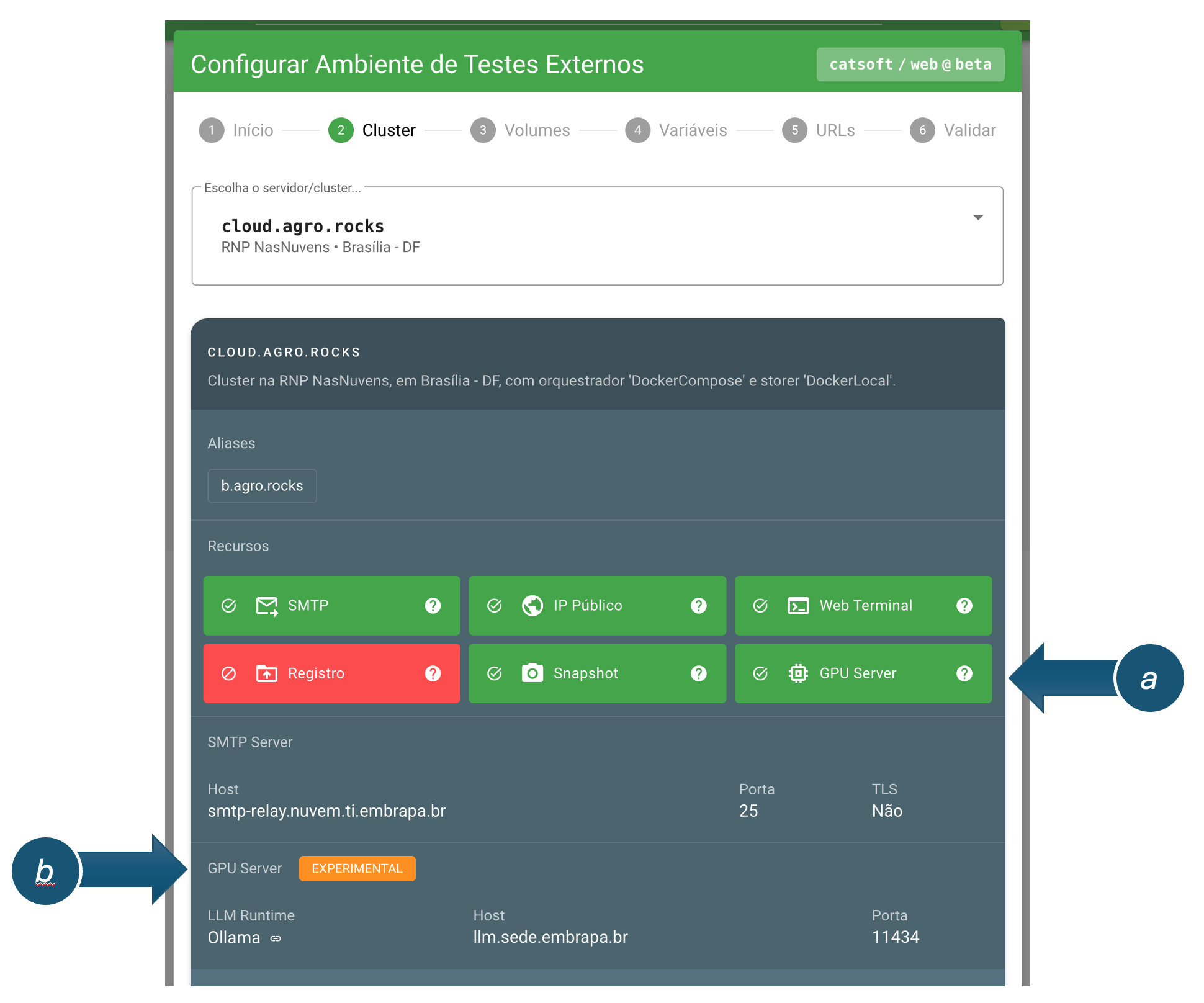
A partir da aplicação instanciada no cluster, poderão ser realizadas chamadas à API disponibilizada pelo LLM Runtime. Por exemplo, se estiver utilizando o N8N, instanciado a partir do boilerplate correlato, você poderá criar uma credencial do Ollama com a URL e porta indicadas:
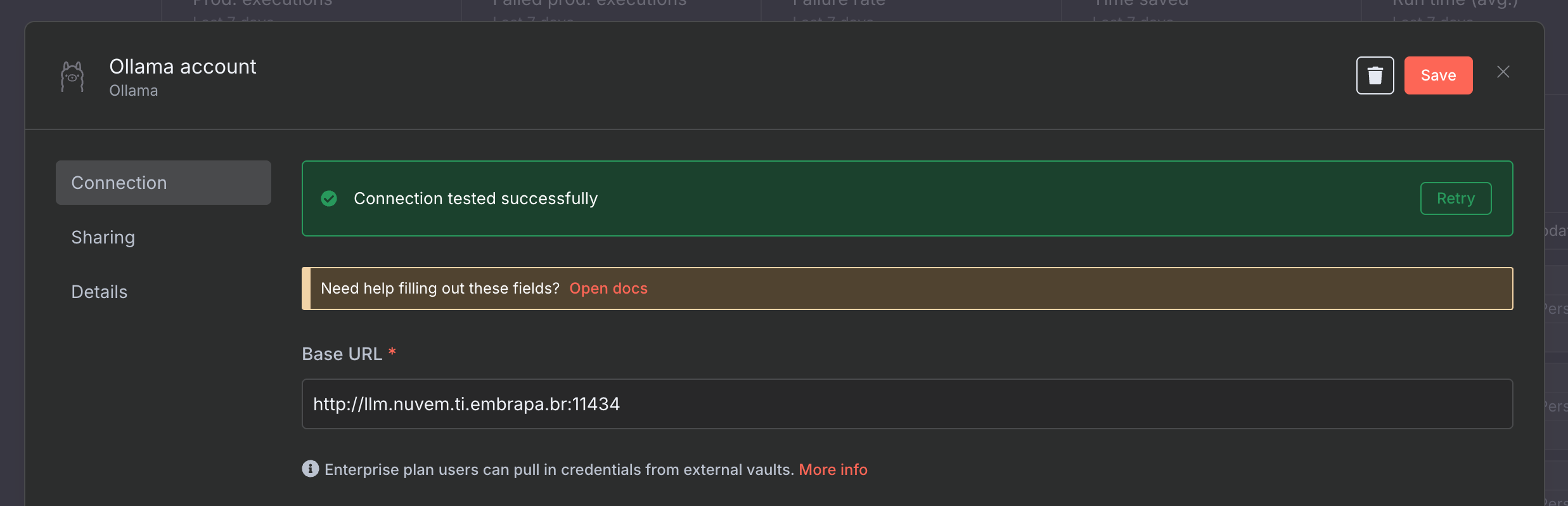
Feito isso, as LLMs disponibilizadas no GPU Server estarão à disposição no momento da criação dos workflows. Por exemplo, ao inserir um nó do tipo “AI Agent” no N8N, no chat model será possível vincular as credenciais (a) e ele listará os modelos disponíveis no GPU Server (b) para serem utilizadas pelo nó:
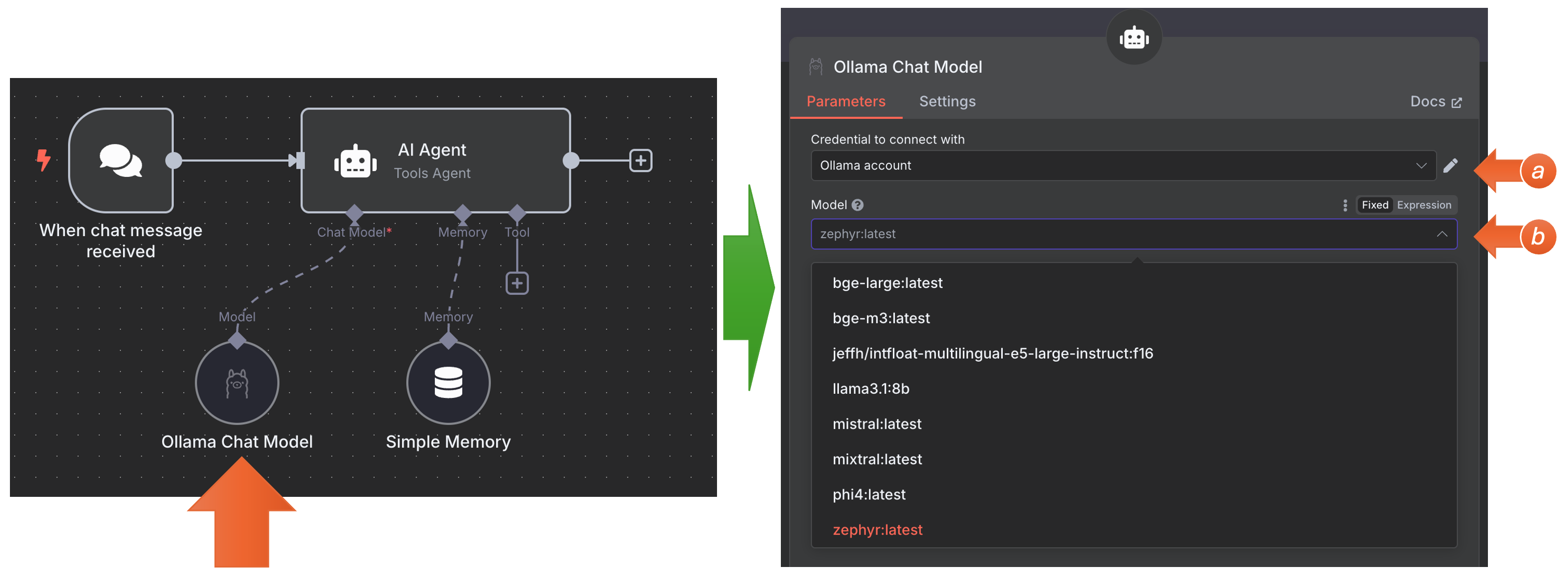
As LLMs disponíveis podem ser utilizadas:
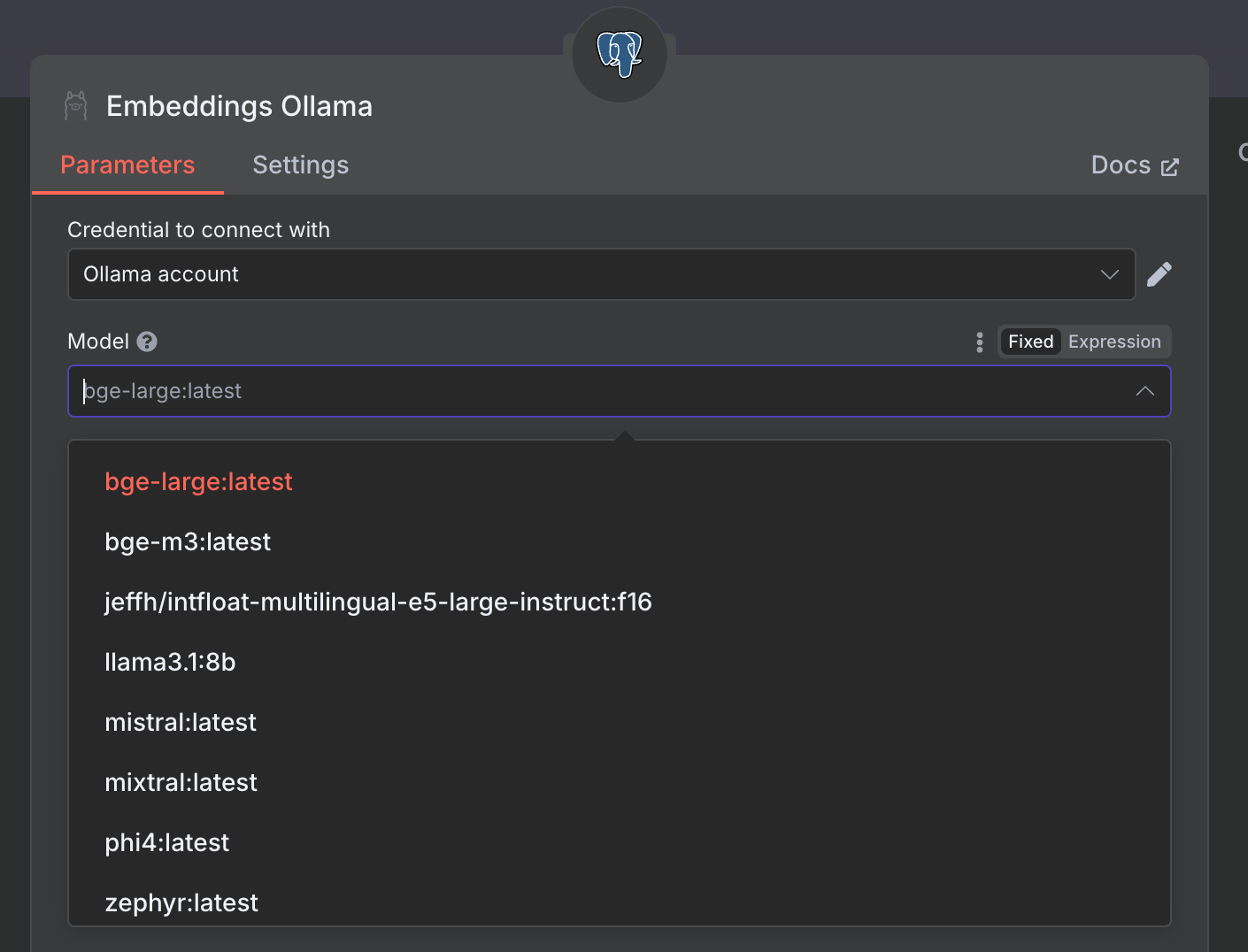
a. no processo RAG para geração de embeddings:
Ao montar um workflow para geração de um BD com vetores visando RAG, pode-se utilizar um nó do tipo “Embeddings Ollama”. Quando escolher as credenciais configuradas, serão listados todos os modelos disponíveis. Você pode consultar o melhor modelo para ser utilizado no seu contexto, mas um bom modelo genérico disponível para esta finalidade é o bge-large:
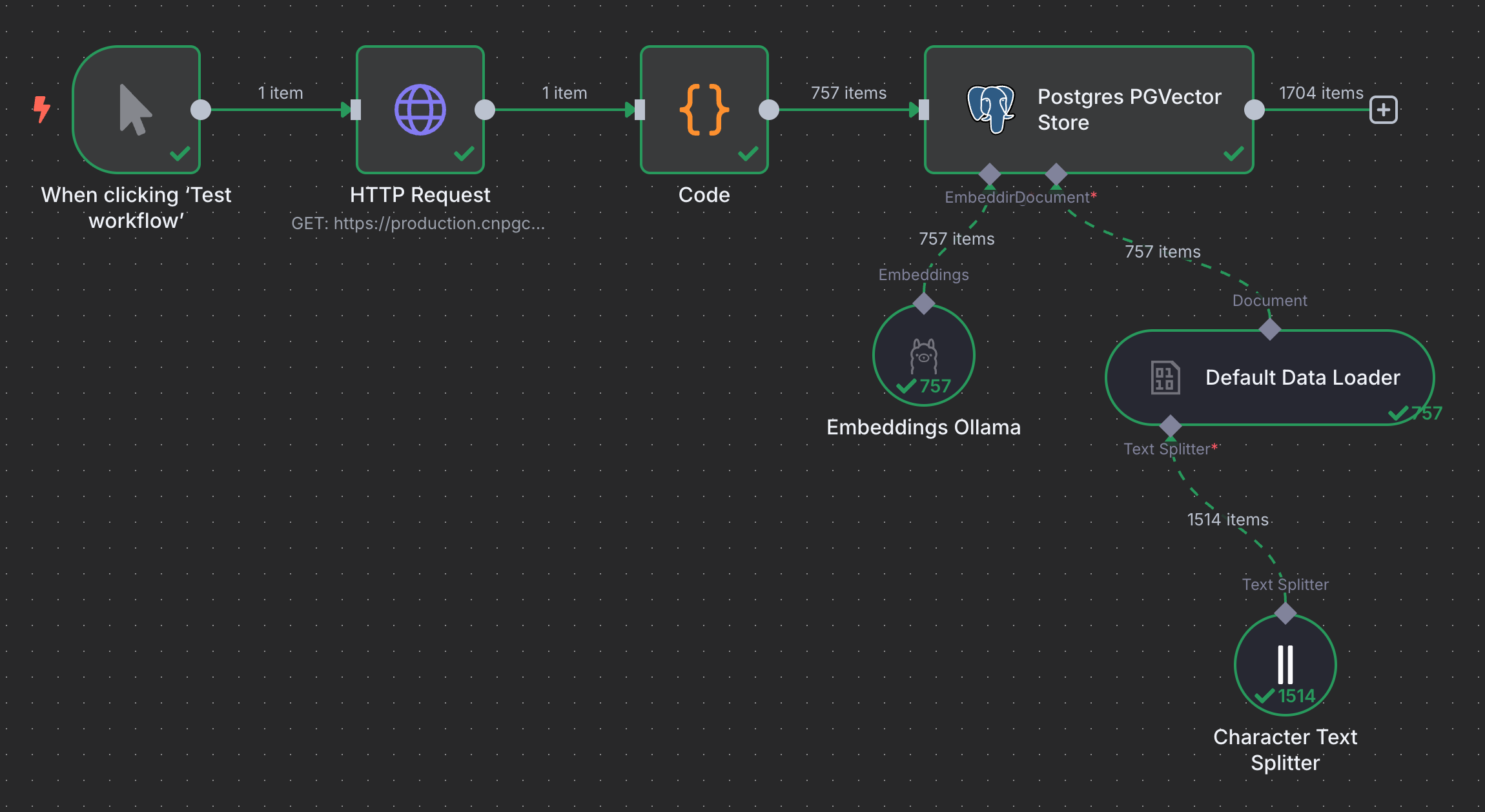
No exemplo abaixo foram extraídas perguntas e respostas da API do SAC Gado de Corte e utilizado o modelo bge-large a partir do GPU Server para gerar os vetores. Estes foram armazenados no banco de dados PGVector, que acompanha o boilerplate do N8N (subindo como um serviço na stack de containers).
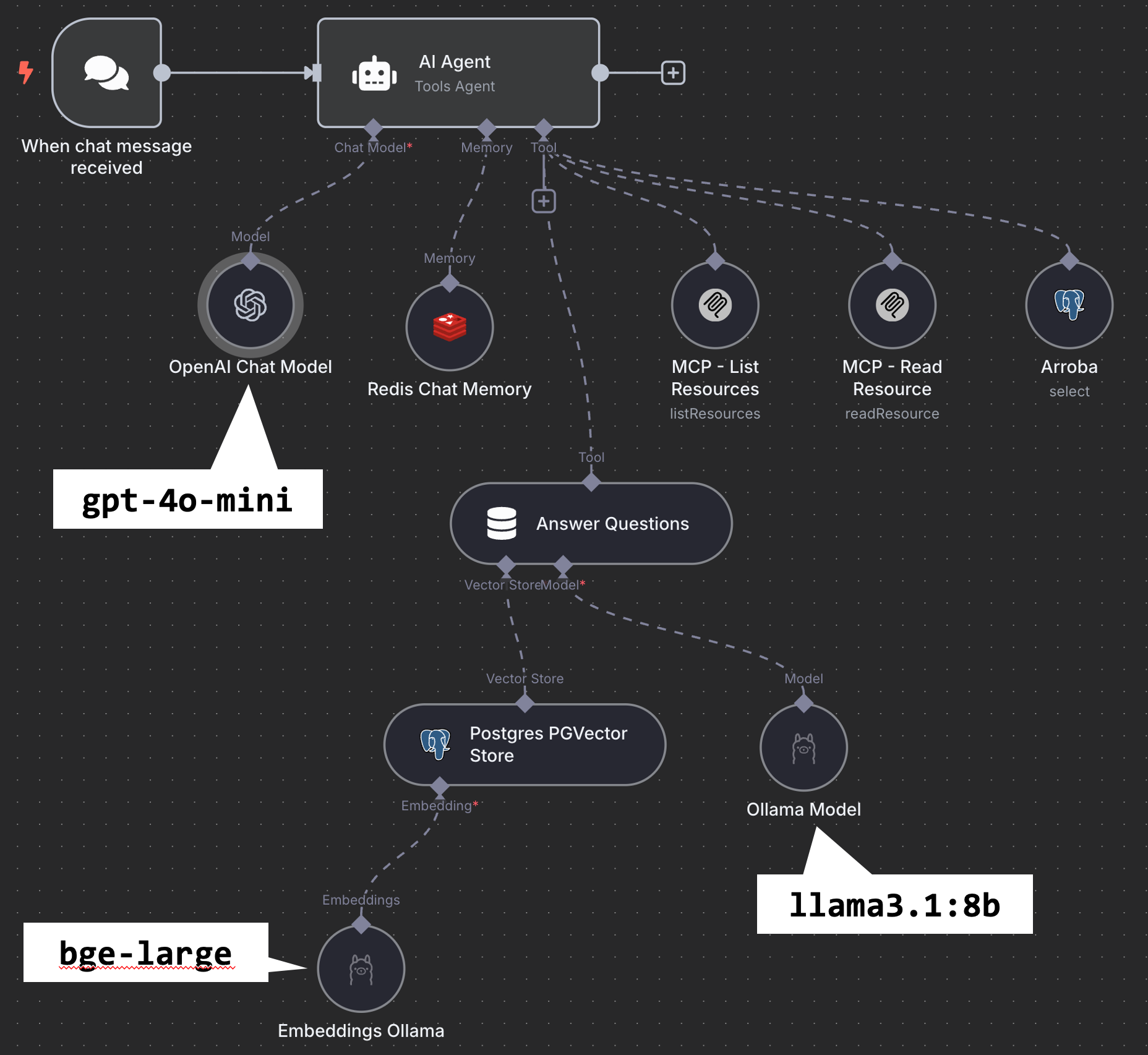
b. pelo agente de IA, nas diversas etapas de tomada de decisão:
No exemplo abaixo, é utilizada a conexão com o Ollama rodando no GPU Server para recuperar as os vetores do PGVector gerados no item anterior (por meio do modelo bge-large) e também para a escolha das melhores respostas (por meio do modelo llama3.1:8b). Para a interação com o usuário, foi utilizada a API bilhetada do OpenAI (e o modelo gpt-4o-mini).
Cabe às equipes testar qual a LLM mais indicada para cada procedimento, no contexto do projeto. Vale ressaltar que estas possuem especializações diferenciadas (p.e., em língua portuguesa, em conversas mais longas e complexas, na geração de embeddings, etc). Você pode buscar o modelo no catálogo do Ollama para ver os detalhes ou simplesmente perguntar ao ChatGPT sobre eles.
Atenção! Esta é uma feature experimental e existem diversas limitações e restrições de uso. Por exemplo, o uso das GPUs no servidor se dá de maneira concorrente e, portanto, elas podem estar todas ocupadas e indisponíveis em diversos momentos. O Ollama não permite ainda o uso paralelizado das GPUs, portanto estão sendo disponibilizadas em cada GPU Server apenas LLMs que performem em uma única GPU deste servidor.
Importante também salientar: o Ollama não é a LLM Runtime mais performática! Poderíamos ter resultados melhores com outras alternativas, tal como o vLLM (que é compatível com a API da OpenAI, possui Multi-GPU/MoE automático e é utilizado em produção pelo Chatbot Arena, OpenRouter, dentre outros). Entretanto o Ollama foi escolhido pelo fato de já ter a integração nativa com o N8N, permitindo uma validação inicial da arquitetura como um todo, favorecendo o uso por mais pessoas e fomentando a discussão de melhoria e evolução em IA generativa na Embrapa.
3. Possibilidade de atualizar imagens e apagar containers no restart da build
A funcionalidade de reiniciar as aplicações (que derruba e reinicia todos os seus containers), presente no painel de health check das instâncias de builds, possibilita agora:
-
Atualizar as imagens de containers que foram baixadas diretamente de um registry (tal como o Docker Hub). Ou seja, esta feature não afeta os serviços que têm build (definido no
docker-compose.yml), uma vez que estas imagens já são atualizadas no processo de deploy, mas sim aquelas de serviços na stack de containers que estão indicadas no atributoimage; e -
Apagar completamente o containers, visando um reinício em “ambiente limpo”. O processo irá apagar a network da stack de containers, todos os containers, os volumes implícitos e as imagens que tiveram build local, forçando a recriação destes artefatos do zero.
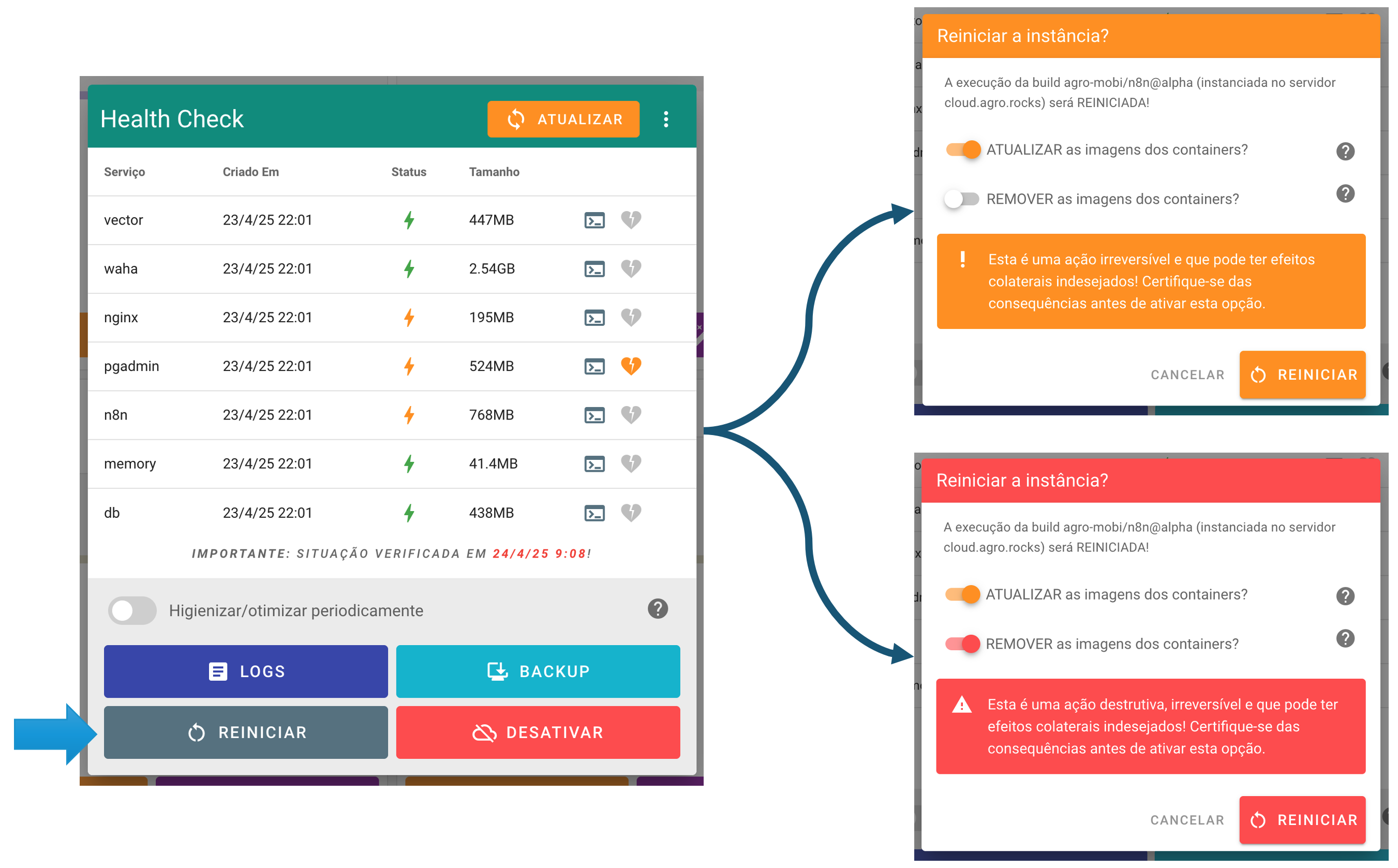
A atualização das imagens é extremamente útil para garantir que ferramentas de apoio (tal como um pgAdmin, Redis Commander, Mongo Express, etc) se mantenham atualizados. Ajuda também a eliminar os CVEs identificados, uma vez que traz a versão mais recente das imagens e, portanto, com as últimas manutenções corretivas e evolutivas. Por exemplo, para atualizar o N8N utilizado em alguns boilerplates citados na seção anterior, basta agora fazer o reinício da aplicação com a opção de “ATUALIZAR” selecionada:
A remoção dos containers pode ser bastante útil também, porém deve ser utilizada com cuidado. Esta feature preserva os dados persistidos, uma vez que não apaga os volumes explícitos das aplicações (aqueles declarados na configuração da build), mas ainda assim se trata de um “procedimento destrutivo” e deve ser encarado como tal. Os comandos que serão aplicados em ambiente remoto estão detalhados nos dialogs de informação e podem ser testados previamente em ambiente local para que o arquiteto da solução tenha ciência plena das consequências.
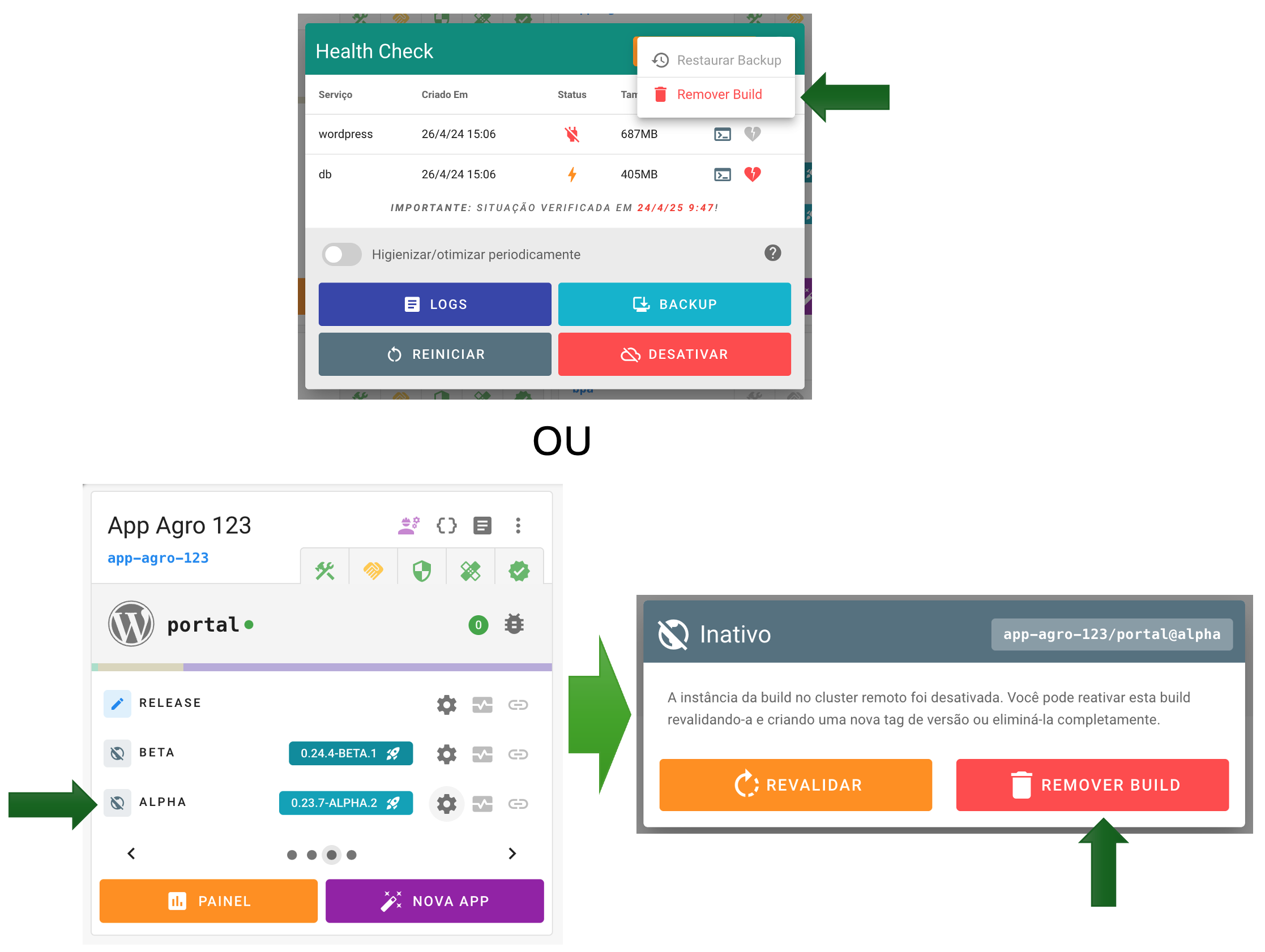
4. Possibilidade de remover completamente a instância (deploy) de uma build
Agora é possível remover completamente o deploy realizado em um cluster. Esta funcionalidade é muito útil para desalocar recursos provisionados por uma aplicação que não será mais utilizada. Por exemplo, aquelas que foram criadas e instanciadas para aprender sobre a própria plataforma Embrapa I/O, para testar features de boilerplates ou outras iniciativas lúdicas.
Atenção! O procedimento irá remover todos os containers, a network da stack, imagens geradas (pelo processo de build), seus volumes de dados (implícitos e explícitos), configurações e metadados.
Reparem que se trata de uma ação irreversível. Ou seja, mesmo que faça um novo deploy desta build no mesmo cluster, todos os dados armazenados nas imagens e volumes não serão recuperados. Portanto, no caso de um novo deploy desta aplicação neste estágio, a mesma estará limpa (“zerada”), apenas com os dados padrão da imagem. Dados históricos, tal como os valores de variáveis de ambiente, também serão perdidos. Certifique-se das consequências e tome precauções (tal como salvar dados importantes) antes de realizar esta ação!
Atenção! É importante frisar que não é possível efetuar backup após a remoção! Assim, é fortemente recomendado efetuar backup da instância da build antes de executar esta ação.
O processo pode ser iniciado de duas maneiras. Se a instância ainda estiver “no ar”, utilize a opção de menu no painel de health check da build. Senão, caso esteja “inativa”, utilize o dialog de revalidação de build:
Um novo dialog será mostrado com um longo disclaimer. Você deverá declarar ciência e executar o processo de validação via envio de PIN:
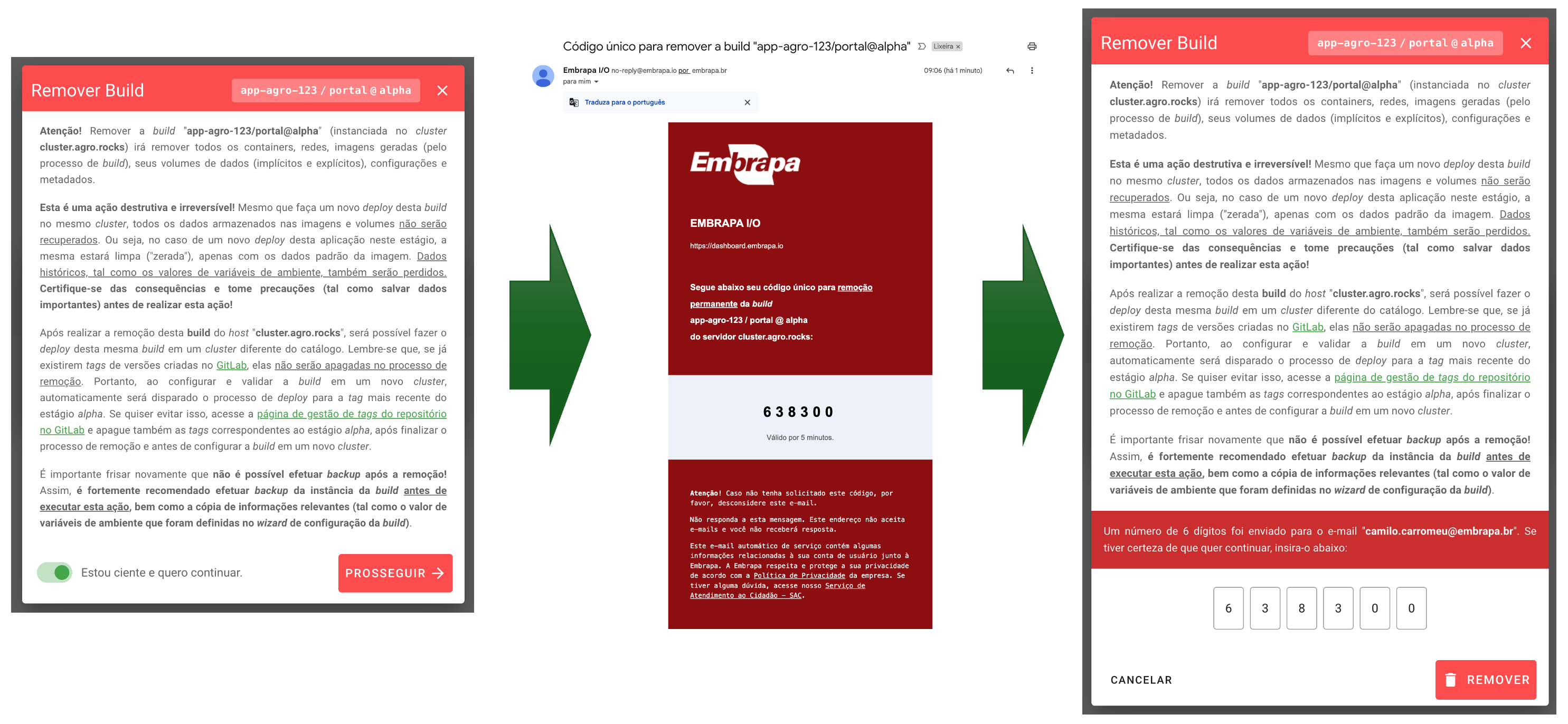
Após ser removida, a build irá voltar para o status de rascunho (DRAFT):
Com isso, será possível configurar novamente e fazer o deploy desta mesma build em um cluster diferente do catálogo.
Atenção! Lembre-se que, se já existirem tags de versões criadas no GitLab, elas não serão apagadas no processo de remoção. Portanto, ao configurar e validar a build em um novo cluster, automaticamente será disparado o processo de deploy para a tag mais recente do estágio da build. Se quiser evitar isso, acesse a página de gestão de tags do repositório no GitLab e apague também as tags correspondentes ao estágio da build, após finalizar o processo de remoção e antes de configurar a build em um novo cluster.
Recomenda-se fortemente o uso desta nova funcionalidade para desprovisionar recursos da infraestrutura em nuvem dos data centers da Embrapa. Para que o Embrapa I/O continue disponibilizando recursos de hardware sem burocracia e amarras, é essencial o uso consciente. Assim, caso tenha instâncias de aplicações de teste ou de treino que não utilize mais, por favor, remova-as dos clusters se possível.
5. Melhorias de segurança na integração de clusters
Por fim, houve melhorias significativas na integração de clusters ao ecossistema da plataforma Embrapa I/O. Agora é possível criar um usuário exclusivo, com permissões restritas, para ativar os pipelines de deploy.
Além disso, para evitar conflitos de rotas com outros hosts na rede do data center que abriga a(s) máquina(s) do cluster, é possível especificar agora em qual subnet interna (faixa de IPs) o orquestrador irá alocar as redes das stacks de containers. Os detalhes destas configurações estão na documentação de configuração de clusters.