A ferramenta Arena de Bots do Embrapa I/O está disponível em:
Trata-se de uma aplicação web para execução de testes cegos em agentes de IA (comumente chamados de chatbots). Por meio dela, é possível criar “torneios” entre dois agentes, que estarão conectados via Webhook ou por uma API OpenAI Compatible.
A ferramenta faz parte do ecossistema do Embrapa I/O e é fortemente inspirada na LMArena, ou seja, uma aplicação web para execução de Testes A/B (ou Testes Cegos). Porém, com a grande diferença que ela permite configurar os torneios, ou seja, gerenciar quais são os agentes a serem testados. Desta forma, as equipes de desenvolvimento dos agentes e as instâncias de qualificação podem submeter o ativo a baterias de testes cegos, realizados por especialistas nos domínios do escopo, conectando o agente a ser testado e uma LLM de controle.
O objetivo é apoiar a validação do agente no que tange avaliação social e subjetiva (com foco na comparação relativa) e ajudar a responder se: (1) o agente desenvolvido entrega “assertividade” com base na preferência percebida pelo especialista e (2) se o agente entrega “mais valor” (ou seja, respostas tecnicamente melhores) do que a LLM genérica (também segundo a percepção relativa do especialista). Adicionalmente, são aferidos e registrados tempos de resposta e outros indicadores úteis. Seu uso pode se dar em conjunto com o emprego de outras metodologias objetivas de testes em IA generativa.
Assim, é possível comparar agentes desenvolvidos em projetos da Embrapa com LLMs genéricas, tal como modelos do ChatGPT (OpenAI), Claude (Anthropic), Gemini (Google), dentre muitos outros. Por meio destes testes cegos com especialistas humanos nos domínios de conhecimento que o agente de IA a ser testado visa atuar, será gerado um relatório analítico com o intuito de demonstrar que o agente contextualizado com dados específicos entrega respostas mais assertivas e com maior valor agregado do que a solução de conhecimento genérico disponível.
A ferramenta permite, portanto, que qualquer usuário crie torneios, que são configurados com dois agentes de IA (o de teste e o de controle). Pode-se então compartilhar um link para este torneio com avaliadores humanos, que devem ser especialistas nos domínios de conhecimento pré-cadastrados. Estes avaliadores enviam prompts que são respondidos por ambos os agentes e, então, avaliam quais deles estão corretos e também qual é o melhor.
Criação e Edição de Torneios
Para criar um torneio, acesse o console da ferramenta e vá em “Criar Torneio”. Preencha o “Título do Torneio” e a “Mensagem de Boas-Vindas”, que são dados que estarão sempre visíveis aos avaliadores.
Em seguida, é preciso definir pelo menos um “Domínio de Conhecimento”, que são as áreas em que o agente foi treinado e portanto em que será testado. Por exemplo, caso se trate de um agente de IA para a pecuária, domínios possíveis seriam: Gado de Corte, ILPF, IPF e ILP. Caso se trate de um agente para atender a processos gerenciais/institucionais, domínios possíveis seriam: RH, Orçamento, Patrimônio e Financeiro.
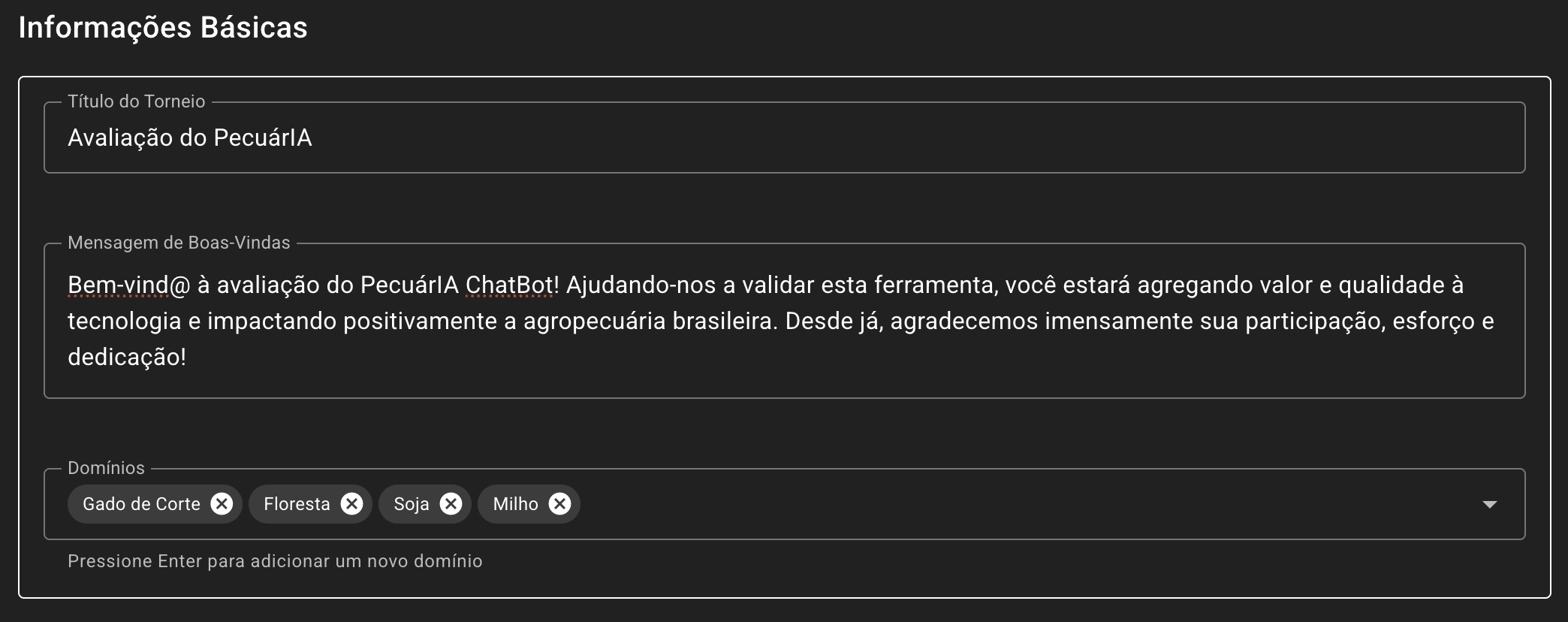
Após inserir as informações básicas do torneio, o usuário deverá configurar os agentes A e B. No primeiro campo, “Nome/Label do Agente”, deverá ser definido um identificador que permita posteriormente reconhecer qual o agente de teste e qual o de controle.
Para cada agente, o usuário deverá então escolher o “Tipo de Integração”, que poderá ser de duas formas:
Via Webhook
Esta é a melhor forma de integrar agentes que tenham sido desenvolvidos no N8N. Basta integrar ao fluxo do seu agente um nó do tipo webhook, conforme a imagem abaixo:
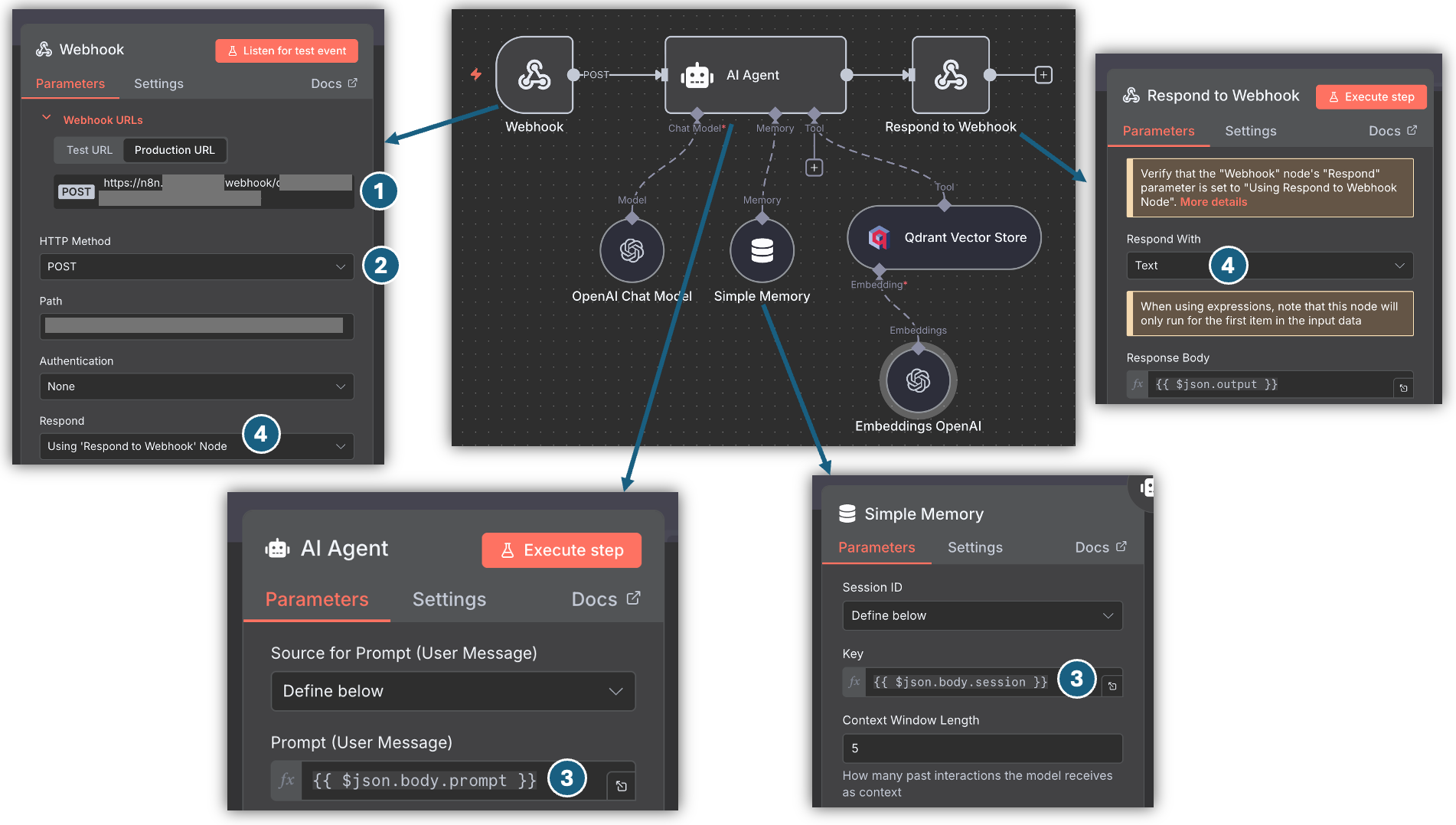
Considere aos itens referenciados acima:
- Na configuração do agente, você deverá inserir no campo “URL do Webhook” a URL gerada pelo N8N;
- O “HTTP Method” no nó Webhook do N8N deverá ser
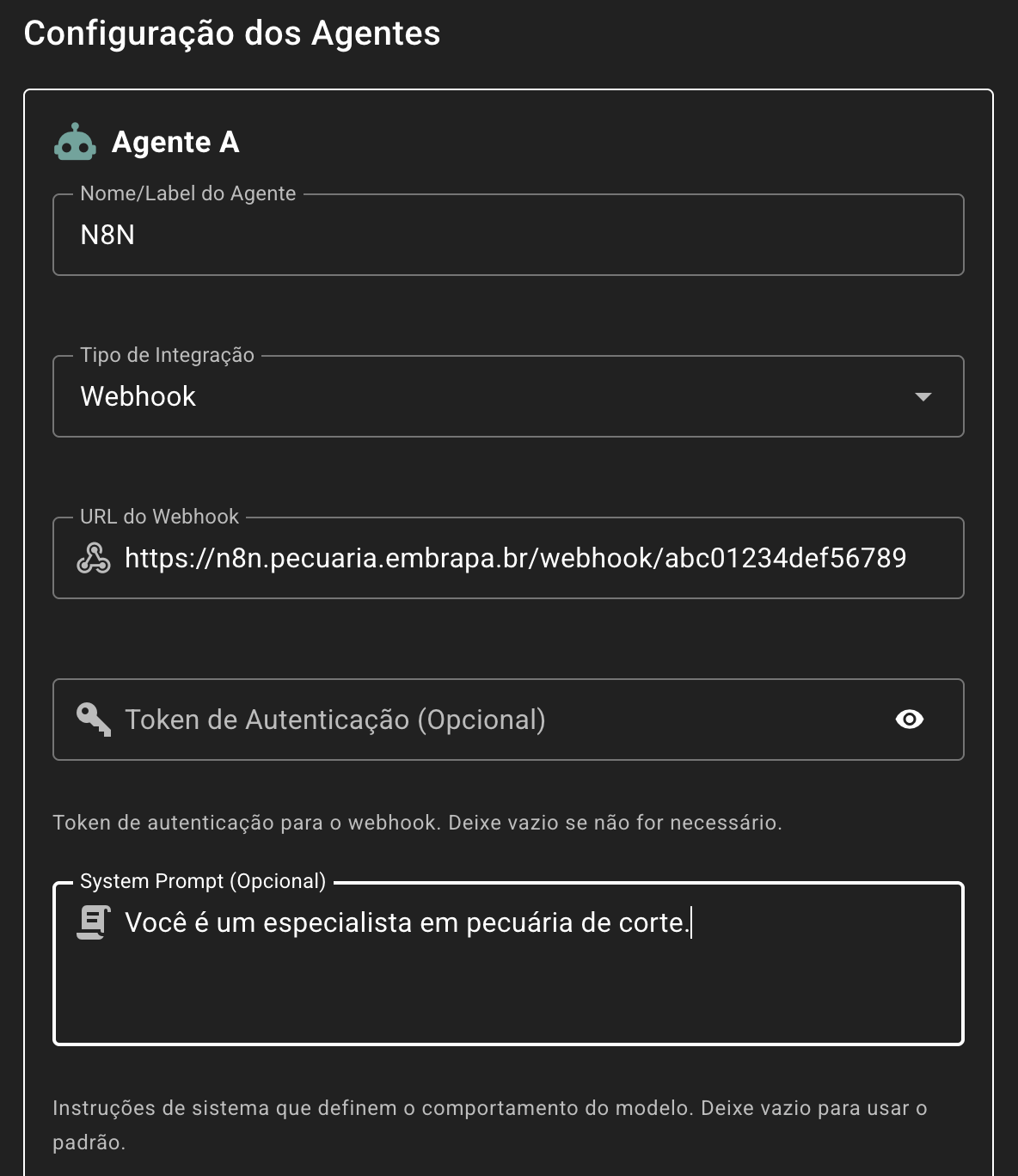
POST; - Para os testes entre os agentes, será enviado ao N8N um JSON no formato abaixo. Repare que o prompt a ser passado para a LLM no N8N está em
$json.body.prompte existe um atributo$json.body.sessionque pode ser utilizado junto aos nós de memória. - Por fim, deverá ser utilizado um nó “Respond to Webhook” para capturar a saída, com a opção de responder no formato texto.
{
"prompt": "<SYSTEM>\nVocê é um especialista em pecuária de corte.\n</SYSTEM>\n\n<USER>\nQual a melhor cultivar para criação de bezerros no Pantanal?\n</USER>",
"timestamp": "2025-09-25T21:39:27.222Z",
"source": "arena.embrapa.io",
"session": "68d5b68f0590ec7e08f10024"
}
No JSON acima (payload da requisição), o atributo prompt está separado em duas tags: <SYSTEM></SYSTEM> e <USER></USER>. Isto ocorre quando é configurado para o agente um “System Prompt”, conforme imagem abaixo:
Caso não seja configurado um “System Prompt”, o valor do atributo prompt será apenas a pergunta do usuário avaliador. No exemplo acima, ficaria:
{
"prompt": "Qual a melhor cultivar para criação de bezerros no Pantanal?",
...
}
Por fim, é possível configurar um token de autenticação, que será passado pelo header: Authorization: Bearer [token].
Via API OpenAI Compatible
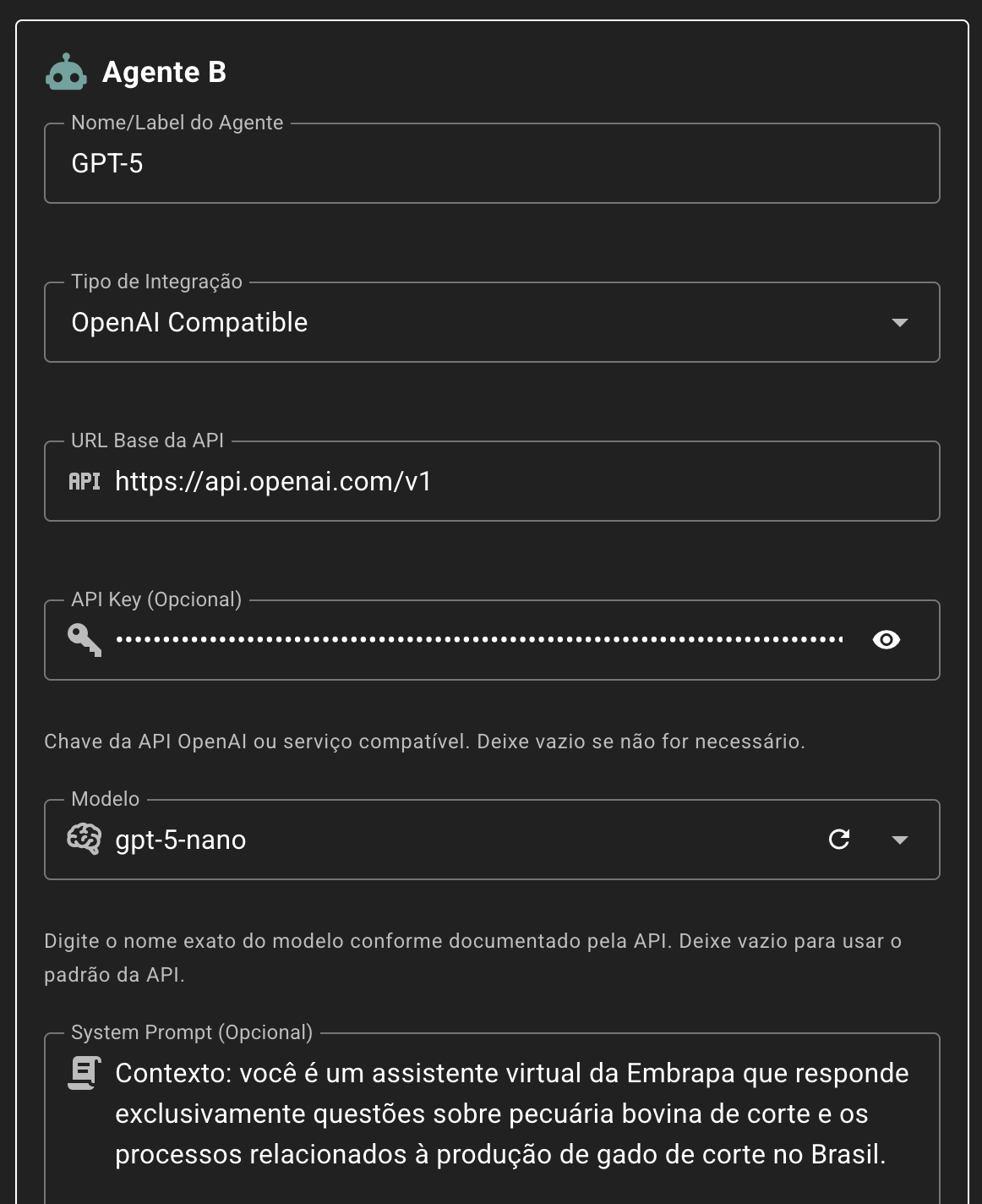
Esta opção é ideal para conectar provedores em nuvem de terceiros ou LLM Runtimes, como o Ollama:
Será enviado à API configurada um prompt estruturado conforme abaixo:
{
"messages": [
{
"role": "system",
"content": "Você é um especialista em pecuária de corte."
},
{
"role": "user",
"content": "Qual a melhor cultivar para criação de bezerros no Pantanal?"
}
],
"max_completion_tokens": 4096,
"model": "claude-sonnet-4-20250514"
}
Repare que o role system é enviada apenas se o campo “System Prompt” for preenchido. Como normalmente este tipo de integração será realizada com o agente de controle, este campo é essencial para que o modelo da LLM Runtime conectada responda de forma similar ao agente que está sendo testado.
Um ponto relevante também é que o limite de tokens é definido pela ferramenta e, neste momento, não pode ser alterado (estando pré-estabelecido em 4096 tokens).
Os campos de integração (“URL Base da API”, “API Key” e “Modelo”) serão definidas conforme o provedor utilizado. Alguns exemplos de provedores que podem ser acessados são:
Ollama
O Ollama fornece compatibilidade experimental com partes do API OpenAI. Pode ser utilizado com qualquer instância do Ollama interna ou externa à Embrapa, que esteja acessível a partir do host hub.arena.embrapa.io. Por exemplo, para utilizar com o GPU Server do data center da GTI na Embrapa Sede, é possível utilizar as seguintes configurações:
- URL Base da API:
http://llm.nuvem.ti.embrapa.br:11434/v1 - Modelo: Pode ser selecionado a partir da lista que é carregada, conforme pode ser vista abaixo.

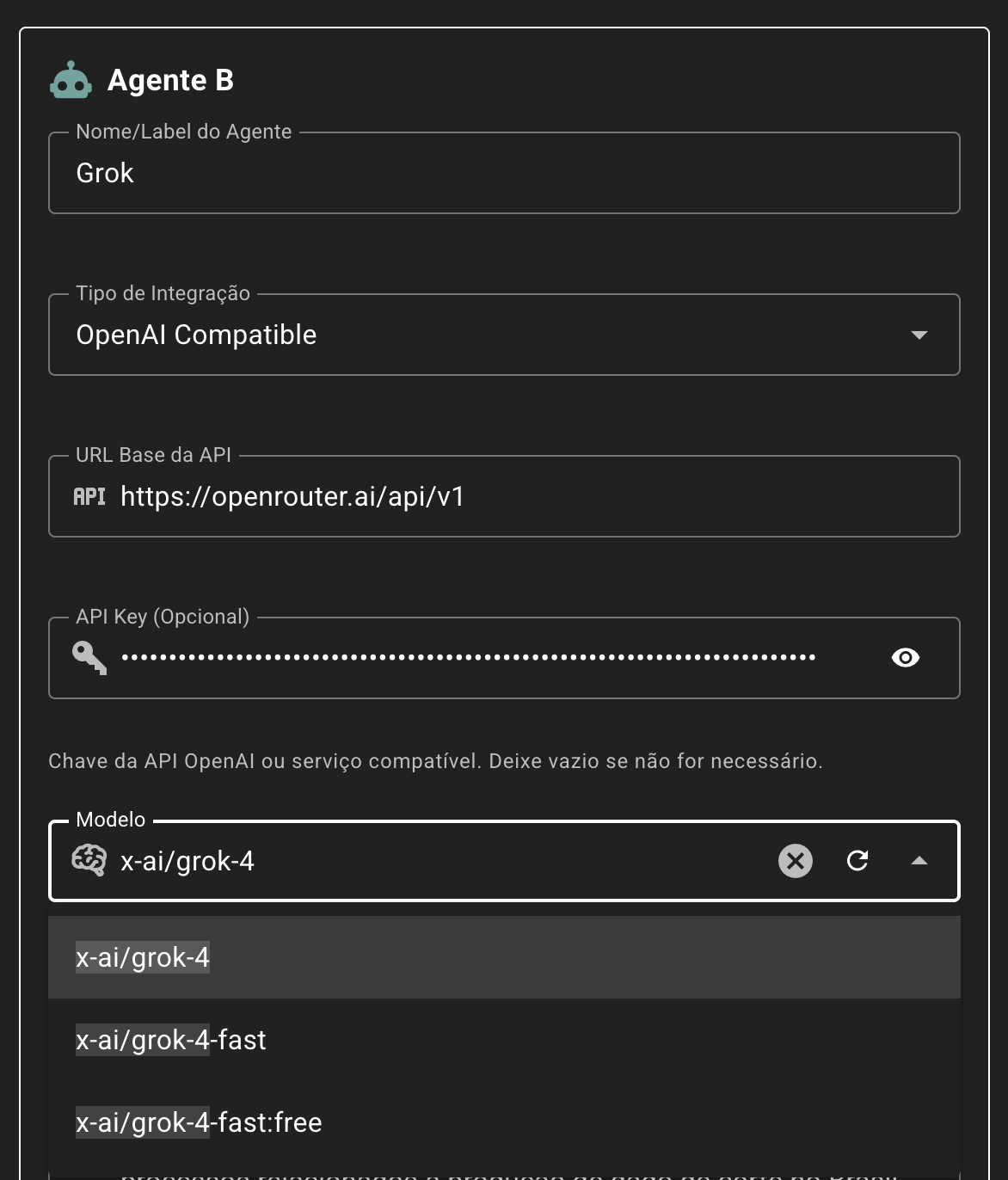
Open Router
O OpenRouter é uma plataforma que funciona como um hub para acesso a modelos de inteligência artificial de diferentes provedores por meio de uma API compatível com o padrão OpenAI. Por exemplo: a API da OpenAI, da Anthropic (Claude), do Google (Gemini), da Mistral, da Meta (LLaMA), da Cohere e outros.
Os esquemas de request e response do OpenRouter são muito semelhantes aos da API do OpenAI, com algumas pequenas diferenças. Para integração, considere os seguintes atributos:
- URL Base da API:
https://openrouter.ai/api/v1 - API Key: Pode ser obtida gratuitamente e existem modelos gratuitos (normalmente com o sufixo
:free) que podem ser utilizados dentro de uma determinada franquia. Ou pode-se colocar um budge (a partir de US$ 5) para uso de todos os modelos disponíveis, consumido conforme número de requisições e tokens trafegados. - Modelo: Uma vez cadastrada a URL e a chave, os modelos disponibilizados serão listados e podem ser selecionados para utilização.
OpenAI ChatGPT
Os modelos da OpenAI do ChatGPT são totalmente suportados, acessíveis pelas seguintes configurações:
- URL Base da API:
https://api.openai.com/v1 - API Key: Deve ser colocado crédito (a partir de US$ 5) e, então, pode ser gerada uma chave por meio do console.
- Modelo: Uma vez cadastrada a URL e a chave, os modelos disponibilizados serão listados e podem ser selecionados para utilização.
Google Gemini
Os modelos do Google Gemini podem ser acessados via uma API REST OpenAI Compatible, com limitações.
- URL Base da API:
https://generativelanguage.googleapis.com/v1beta/openai - API Key: Deve ser gerada no Google AI Studio.
- Modelo: A API da Google compatível com o padrão OpenAI não permite carregar os modelos disponíveis, portanto eles devem ser inseridos manualmente (p.e.,
gemini-2.5-flash-liteougemini-2.5-pro).
Anthropic Claude
A Anthropic fornece uma camada de compatibilidade que permite usar a API no padrão OpenAI, com limitações.
- URL Base da API:
https://api.anthropic.com/v1 - API Key: Deve ser colocado crédito (a partir de US$ 5) e, então, pode ser gerada uma chave por meio do Claude Console.
- Modelo: A API da Anthropic compatível com o padrão OpenAI não permite carregar os modelos disponíveis, portanto eles devem ser inseridos manualmente (p.e.,
claude-sonnet-4-20250514ouclaude-opus-4-1-20250805).
Testando a Conectividade
Ao final da configuração de cada agente é possível testar a conectividade. Por padrão, a ferramenta envia o prompt “Quem é você e qual seu identificador exato de modelo?”, porém ela pode ser alterada. Este teste prévio não é persistido de nenhuma forma e apenas visa garantir que a integração esteja funcional.

Avaliação dos Agentes
Uma vez que o torneio esteja criado e devidamente configurado, já é possível enviar para os avaliadores. Estes devem ser especialistas nos domínios de conhecimento de abrangência do agente de IA a ser avaliado.
O torneio somente estará apto a receber avaliações se estiver “ativo”, portanto o primeiro passo é clicar no ícone correlato para ativá-lo. Você pode ativar e desativar torneios a qualquer momento.
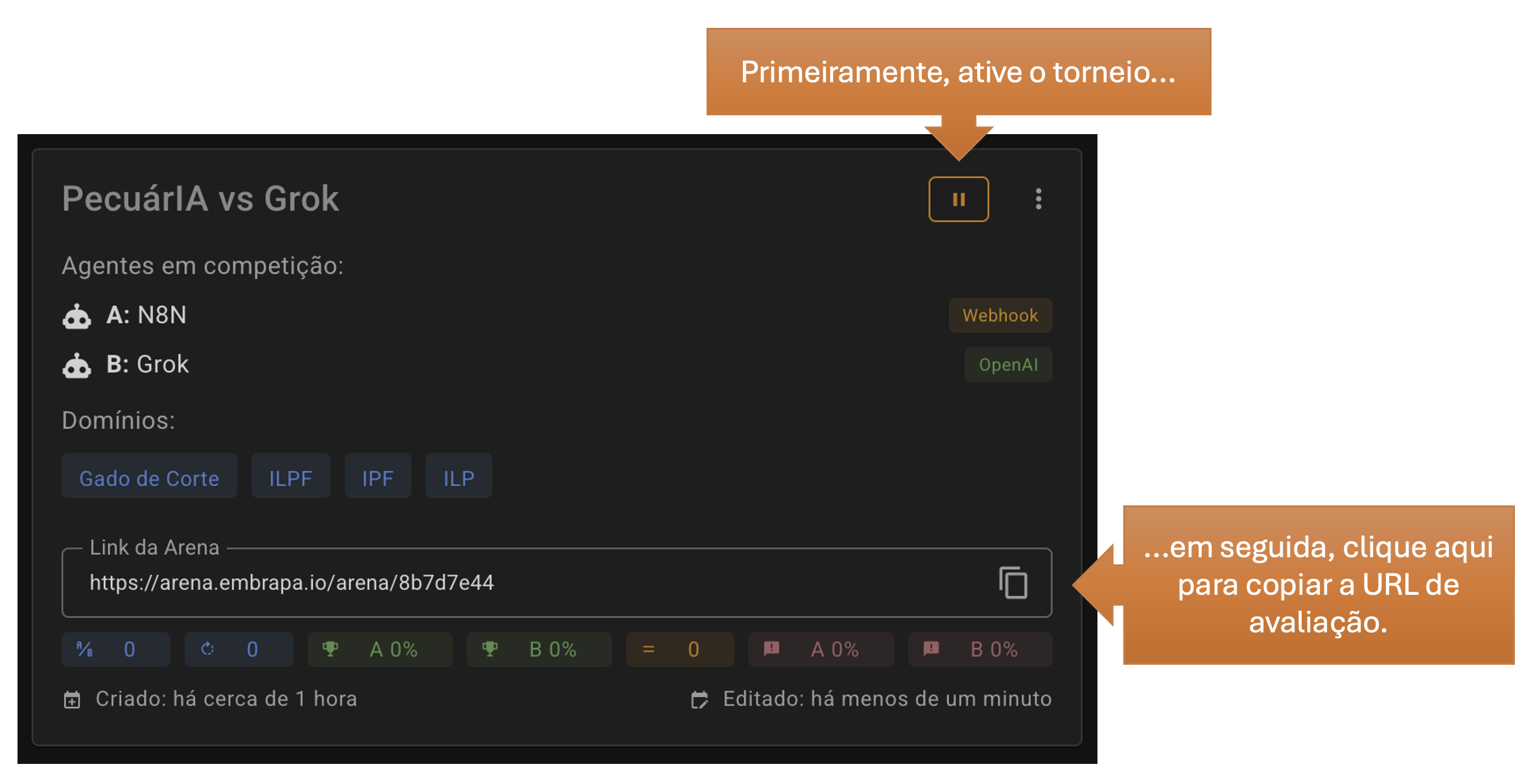
Em seguida, copie o link de avaliação. Ele pode ser enviado por WhatsApp e outros aplicativos de mensagens, bem como por e-mail ou qualquer outra forma. Pode-se, inclusive, gerar um QR Code para ficar disponível em apresentações ou material impresso.
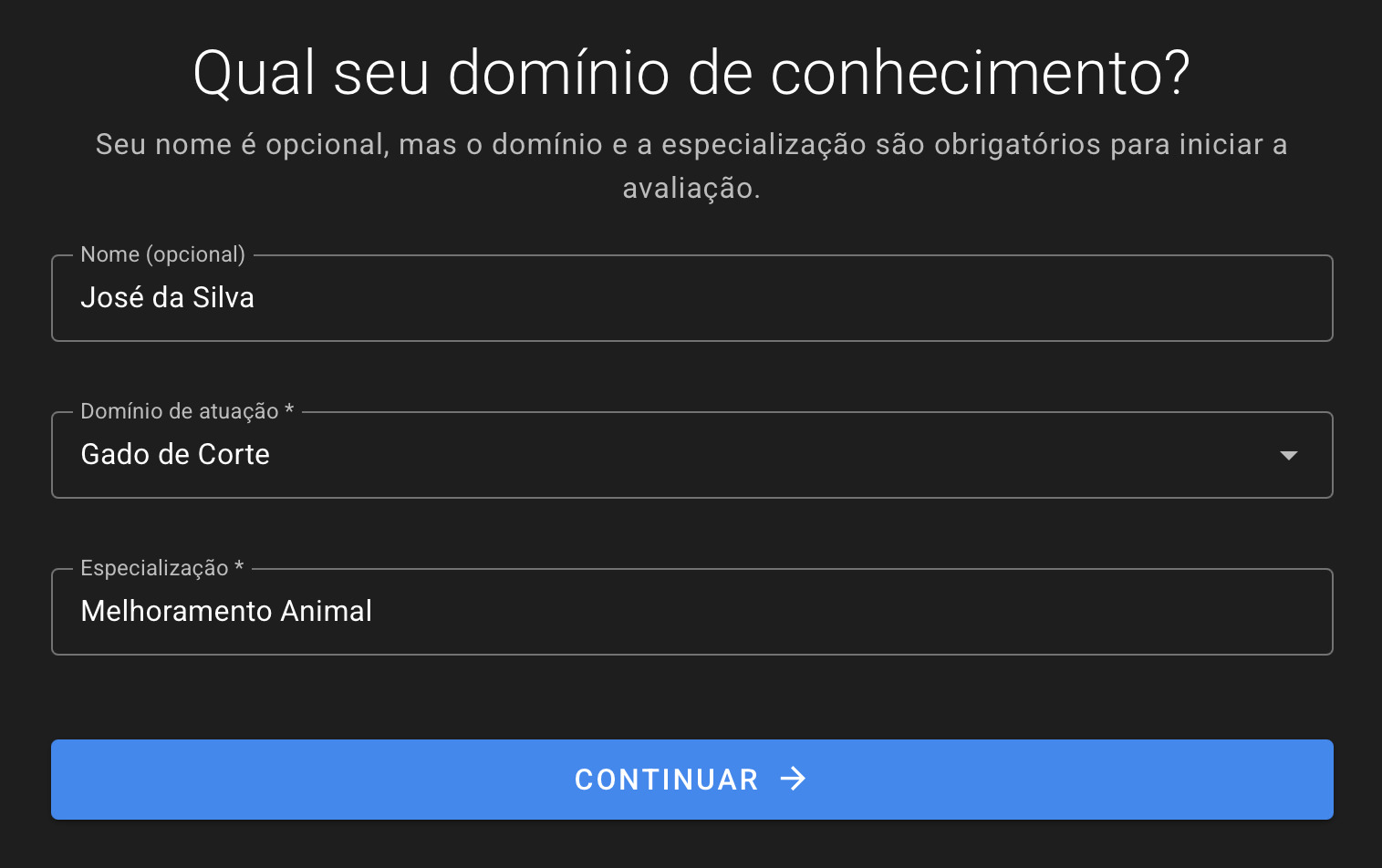
Quando o usuário avaliador acessar o link, ele precisará aceitar alguns disclaimers sobre aviso de privacidade, uso de dados e termos de uso. O sistema não coleta nenhum dado pessoal obrigatório do avaliador, podendo ser realizada uma avaliação anônima. Após dar ciência, o usuário deve preencher um formulário com nome (campo opcional), o domínio de conhecimento (que será selecionado dentre os previamente cadastrados na criação do torneio) e sua especialização.
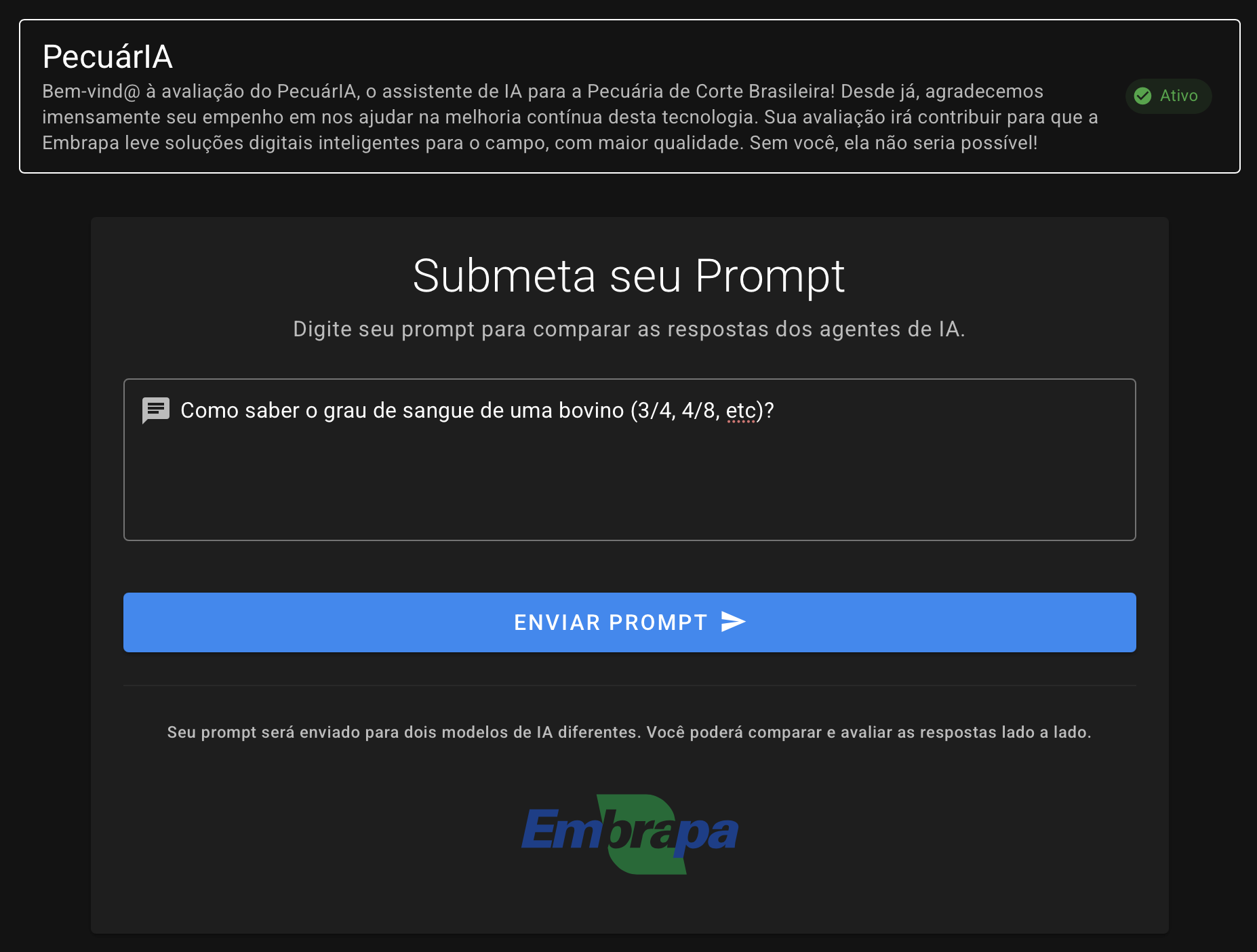
Após breves instruções, o avaliador pode iniciar o teste enviando um primeiro prompt (até 2.000 caracteres):
O usuário precisa então aguardar o processamento pelos dois agentes IA:
O avaliador irá receber as respostas em duas caixas lado-a-lado. Ele deverá então escolher a melhor resposta dentre 6 opções possíveis (e auto-explicativas): “somente A acertou”, “A é melhor”, “empate”, “ambos ruins”, “B é melhor” e “somente B acertou”. Poderá também inserir uma observação com eventuais apontamentos e contribuições (até 1.500 caracteres).
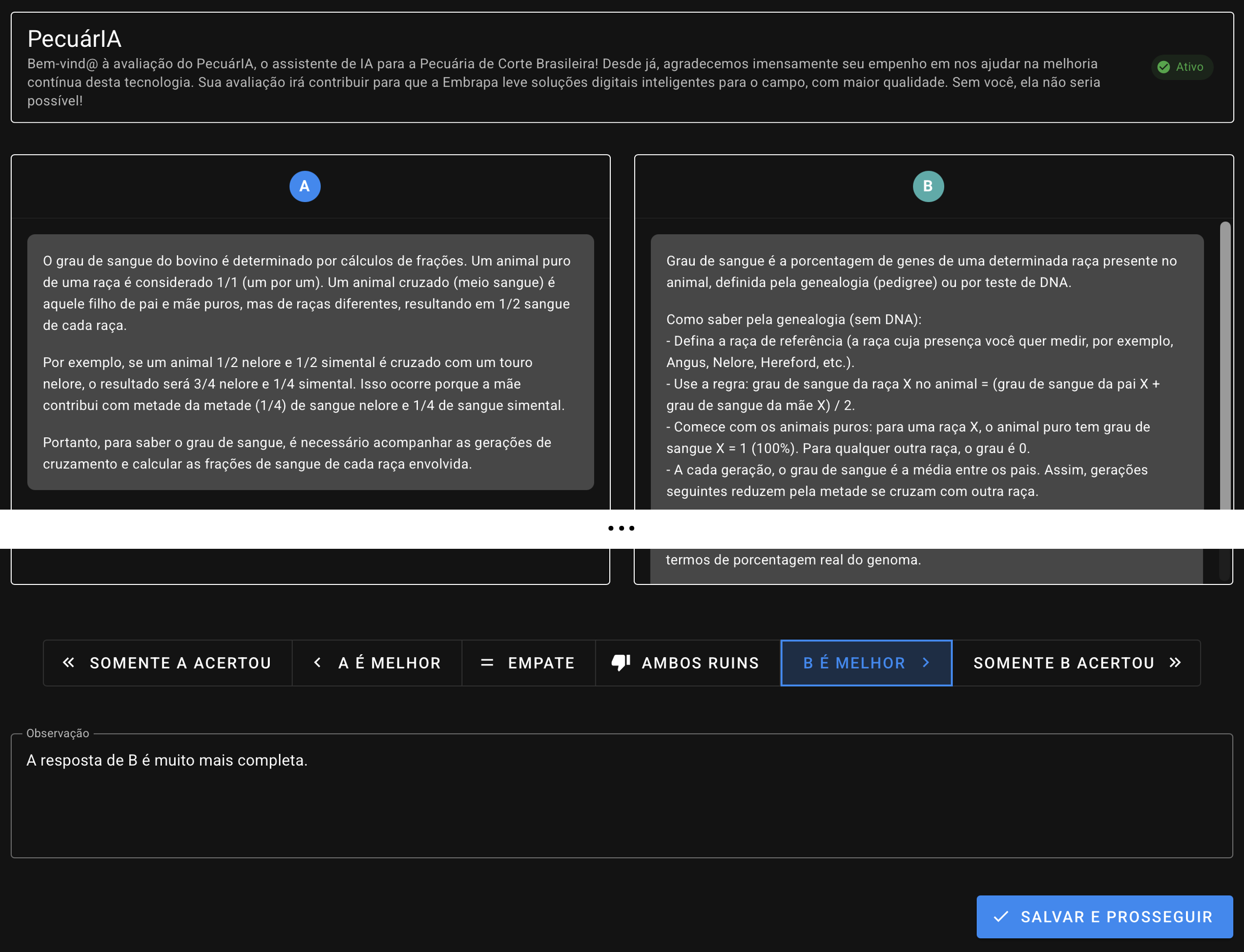
Ao clicar em “Salvar e Prosseguir”, a avaliação recém realizada é armazenada no banco de dados da ferramenta e o ciclo recomeça novamente na tela de envio de prompt. O avaliador pode realizar quantas avaliações quiser.
Obtendo os Resultados
É possível acompanhar os testes pelo próprio card do torneio, que mostra de forma resumida as avaliações realizadas:
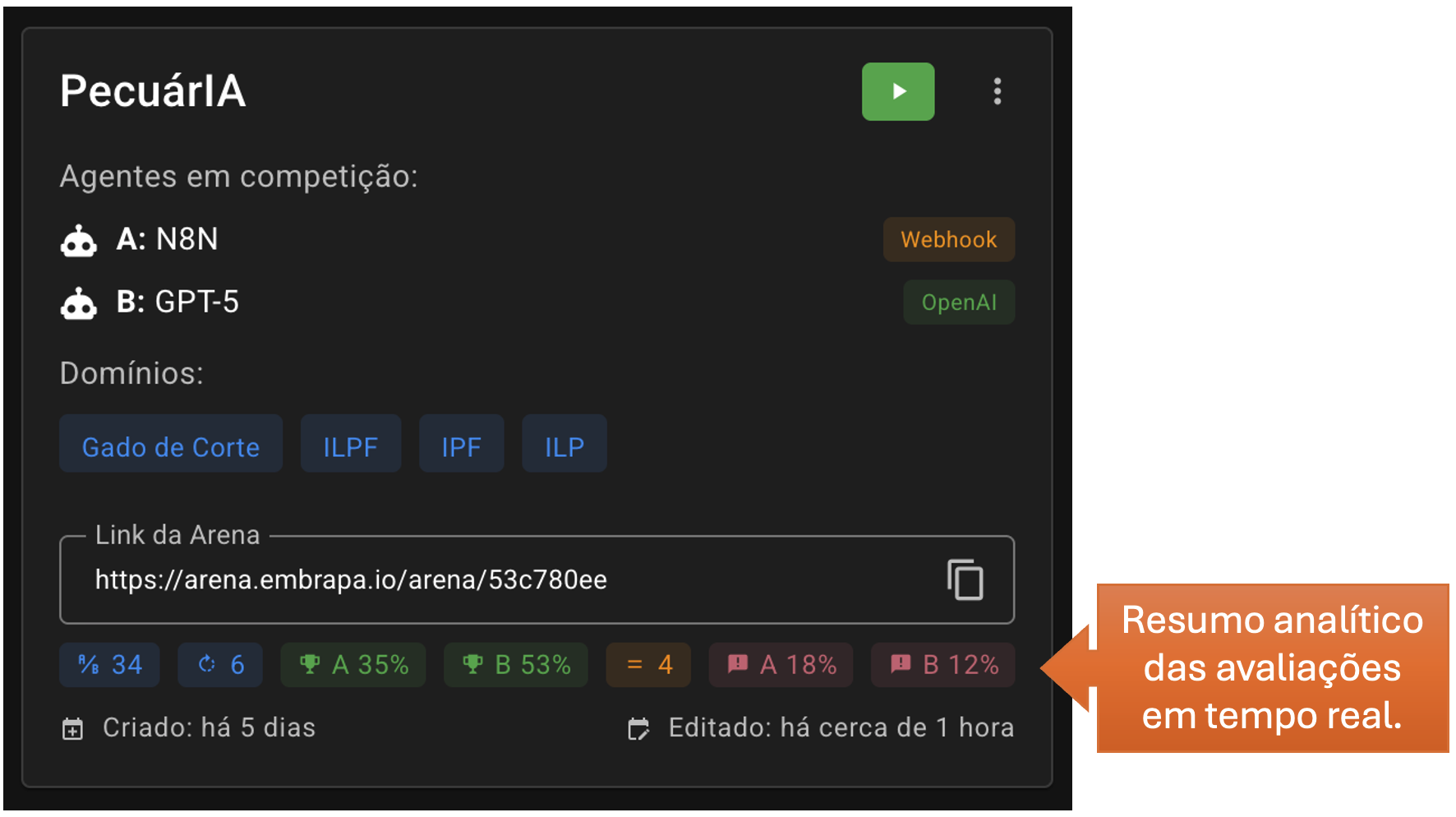
Em ordem da esquerda para a direita, a linha apontada acima irá mostrar: a quantidade de avaliações realizadas, a quantidade de rounds, as taxas de vitória dos agentes A e B, a taxa de empate e a taxa de erros dos dois agentes.
A Taxa de Erro do Agente A é a soma da quantidade de vezes em que os avaliadores marcaram as opções “somente B acertou” e “ambos ruins”, dividido pelo total de avaliações realizadas.
Para extrair todas as avaliações visando gerar um relatório analítico completo, é fortemente recomendado desativar o torneio e, pelo menu de contexto do card, exportar uma planilha Excel com todos os dados:
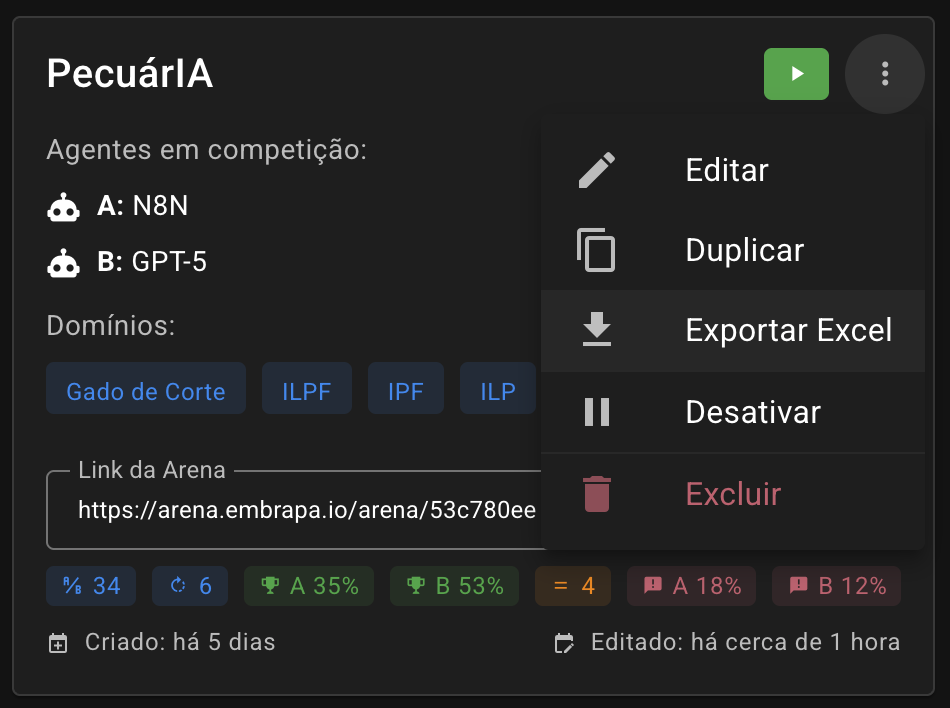
A planilha resultante entrega algumas informações analíticas a partir dos dados e também toda a sequência de avaliações (dados brutos), permitindo gerar outros insights, gráficos e indicadores relevantes para compreender a eficácia do agente de IA em teste. Além de trazer a avaliação em si das respostas de ambos os agentes, são entregues o prompt original do usuário, as duas respostas dos agentes A e B, o voto e a observação do avaliador, o tempo de resposta humano e o tempo de resposta individual de cada um dos agentes de IA.

Além disso, os dados brutos são organizados em rounds com um ID único, permitindo que as avaliações de outros torneios sejam mesclados para possibilitar uma análise mais profunda. Assim, é possível fazer diversos torneios em que o agente de teste é o mesmo, porém o de controle varia (p.e., modelo Sonnet, ChatGPT, Grok, Qwen, etc) e depois mesclar estas linhas para gerar relatórios com maior diversidade de comparações.