A plataforma Embrapa I/O passa a contar com uma página pública de status além de ter sido aprimorada sua stack centralizada de observabilidade, trazendo transparência sobre a disponibilidade dos serviços e visibilidade completa sobre a infraestrutura dos recursos no data center.
Status Page
A nova Status Page está disponível em:
Construída com o Gatus, a página monitora continuamente todos os serviços, hosts e clusters da plataforma e exibe o estado atual e o histórico de disponibilidade (uptime) em uma interface pública:
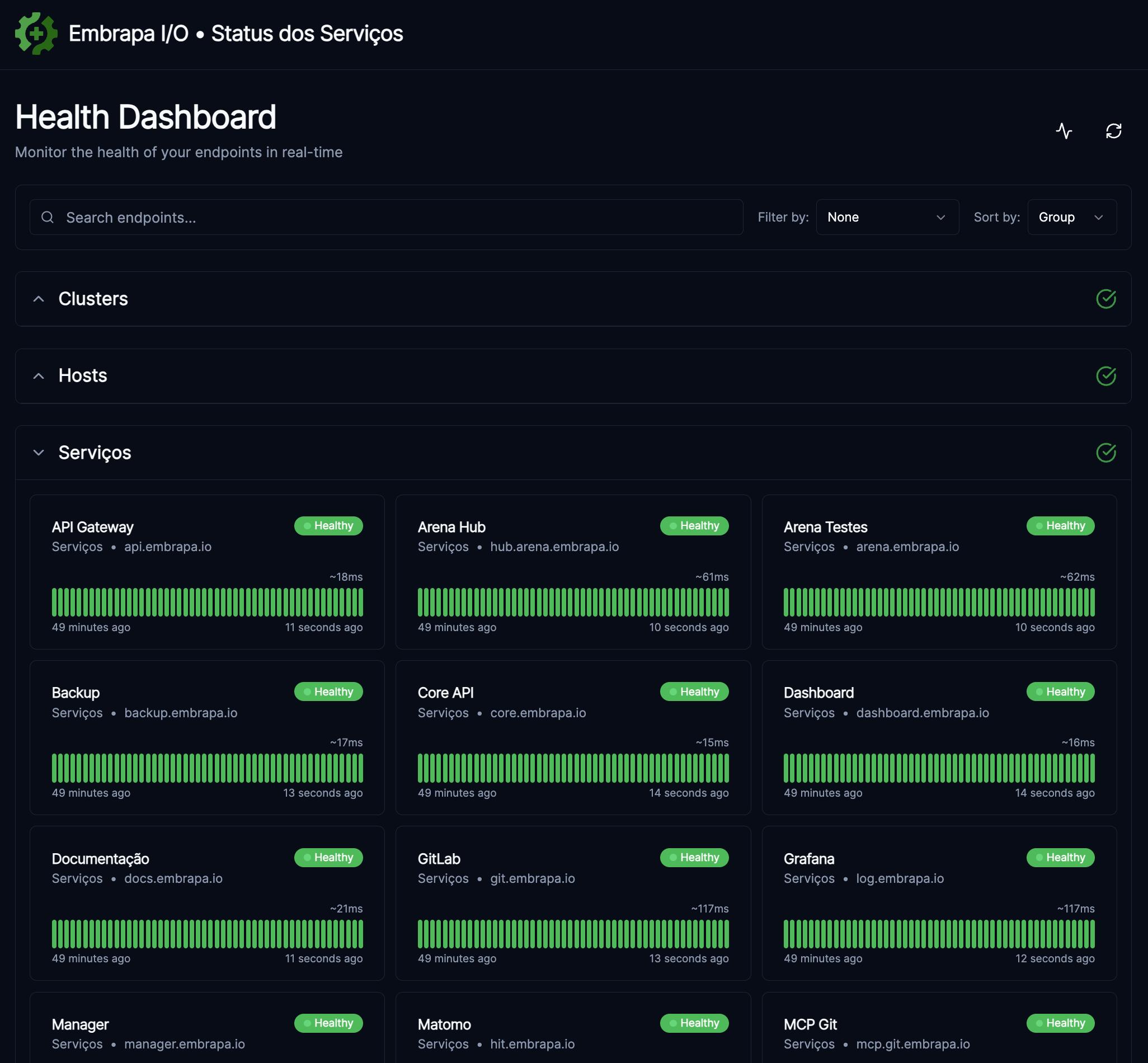
O que é monitorado
O monitoramento está organizado em três grupos:
Serviços
Verificações HTTP a cada 60 segundos para todos os serviços da plataforma, incluindo:
- Core API, Dashboard, Manager e Portal — serviços centrais da plataforma
- GitLab, Matomo, Sentry e SonarQube — ferramentas de apoio ao desenvolvimento
- Grafana, ThingsBoard e N8N — painéis e automação
- MCP Servers (Principal, Logs e Git) — integração com assistentes de IA
- Documentação, API Gateway e Backup — serviços de suporte
- Arena Hub e Arena Testes — ambientes do projeto Arena
- Portainer — painéis de gestão de containers em cada cluster
Cada endpoint é verificado quanto ao código de resposta HTTP (200) e tempo de resposta (< 5s).
Hosts
Monitoramento de espaço em disco das máquinas virtuais do data center (*.embrapa.io), consultando métricas do Prometheus via PromQL. O check é considerado saudável quando o disco possui pelo menos 15% de espaço livre.
Clusters
O mesmo monitoramento de disco é aplicado aos servidores da rede de clusters (*.agro.rocks), garantindo que os nós de deploy de aplicações tenham espaço suficiente para operar.
Os dados são persistidos, preservando o histórico de disponibilidade entre reinicializações do serviço.
Stack de Observabilidade
A Status Page faz parte de uma stack centralizada de observabilidade que agrega logs e métricas de toda a infraestrutura. Os componentes são:
Grafana — Painel unificado
O Grafana é o painel centralizado de visualização, acessível em https://log.embrapa.io. Nele, a equipe de operações pode explorar logs, consultar métricas de infraestrutura e configurar alertas com notificação por e-mail.
Loki — Agregação de logs
O Grafana Loki recebe e indexa logs de duas fontes:
- Grafana Alloy — Logs do systemd journal e de
/var/logde cada host - Docker Loki Driver — Logs de containers enviados diretamente pelo daemon do Docker
Os logs são acessíveis pelo Grafana e também via MCP Server de Logs, permitindo consultas por assistentes de IA.
Prometheus — Métricas de infraestrutura
O Prometheus opera como receptor de métricas. Recebe métricas de CPU, memória, disco e rede de todos os hosts, coletadas pelo Grafana Alloy.
Essas métricas alimentam os dashboards do Grafana e também as verificações de disco da Status Page (via consultas PromQL internas).
Grafana Alloy — Agente nos hosts
O Grafana Alloy é instalado em cada máquina virtual do data center como agente de coleta. Com uma configuração única e idêntica para todos os hosts, ele:
- Coleta logs do systemd journal (últimas 12h no startup) e de
/var/log/*.log, enviando ao Loki - Coleta métricas de CPU, memória, disco, filesystem e rede via
prometheus.exporter.unix, enviando ao Prometheus - Identifica automaticamente o hostname e IP do host, aplicando labels para facilitar a filtragem
Alertas via Grafana
O sistema de alertas é gerenciado diretamente pelo Grafana, com notificações por e-mail (SMTP) configuradas nativamente. Isso permite criar regras de alerta baseadas tanto em métricas do Prometheus (p.e., disco cheio, CPU elevada) quanto em padrões de logs do Loki (p.e., erros recorrentes).